





Web Scraping Với Java Như Thế Nào?

Bạn đã bao giờ được giao một công việc đi thống kê dữ liệu về một chủ đề nào đó chưa? Về cơ bản công việc đó sẽ là lên mạng tra cứu và tìm các trang chứa thông tin cần thiết và copy nó về. Thế nhưng sau khi đã chăm chỉ copy kha khá dữ liệu thì sếp bạn yêu cầu một khối lượng gấp 100, 1000 lần số lượng bạn đã thống kê.
Thật khó để giải quyết yêu cầu trên bằng cỗ máy chạy bằng cơm vậy nên để giải quyết bài toán này mình đã nghĩ đến Web Scraping.
1. Web Scraping là gì ?
Web scraping là việc trích xuất dữ liệu từ một trang web. Thông tin này được thu thập và tổng hợp để đáp ứng một nhu cầu nào đó từ người dùng như :
- Trích xuất giá sản phẩm để từ đó phân tích giá sản phẩm trên thị trường
- Trích xuất dữ liệu về cổ phiếu
- Trích xuất dữ liệu về việc làm
- Copy sản phẩm để làm dropshipping
- Copy dữ liệu để học tập
- Phục vụ dữ liệu cho data mining….
Tóm lại Web scraping có thể làm rất nhiều việc. Điều quan trọng là bạn sử dụng dữ liệu đó như thế nào để mang lại hiệu quả cho mình
2. Thực hành web scraping với Java
Vì sao mình chọn ngôn ngữ Java đơn giản vì bản thân mình sử dụng nó tốt nhất và cũng thích nó nhất
- Sử dụng thư viện jsoup.org một công cụ mạnh mẽ để trích xuất dữ liệu. Bạn có thể sử dụng nó để phân tích HTML từ URL, tệp và Chuỗi. Nó cũng có thể thao tác các phần tử hoặc thuộc tính HTML.
- Trang web mình hướng tới là trang web mình đang luyện thi TOEIC luôn englishfreetest.com vì trang đó có một loạt bài ngữ pháp tiếng anh rất hay và mình muốn lấy dữ liệu tạo một file riêng cho mình để đỡ tốn dung lượng 4G hàng ngày =))
Các bước thực hiện:
- Phân tích website
- Lấy danh sách các bài viết từ danh mục bài viết trên website
- Sau khi đã lấy được danh sách các bài viết cần lấy nội dung từng bài viết đó
2.1. Phân tích website
Phân tích trang danh mục bài viết
Truy cập trang danh mục bài viết và dùng công cụ “Developer tools – F12” thần thánh
Ta sẽ thấy được chỗ cần tìm link bài viết được nằm trong thẻ H2 con của DIV class = “post-content”
.PNG)
Phân tích trang nội dung bài viết
Tiếp tục sử dụng công cụ “Developer tools – F12” như trên
Ta sẽ thấy được chỗ cần tìm, nội dung bài viết nằm ở <article class=”post post-large blog-single-post”>
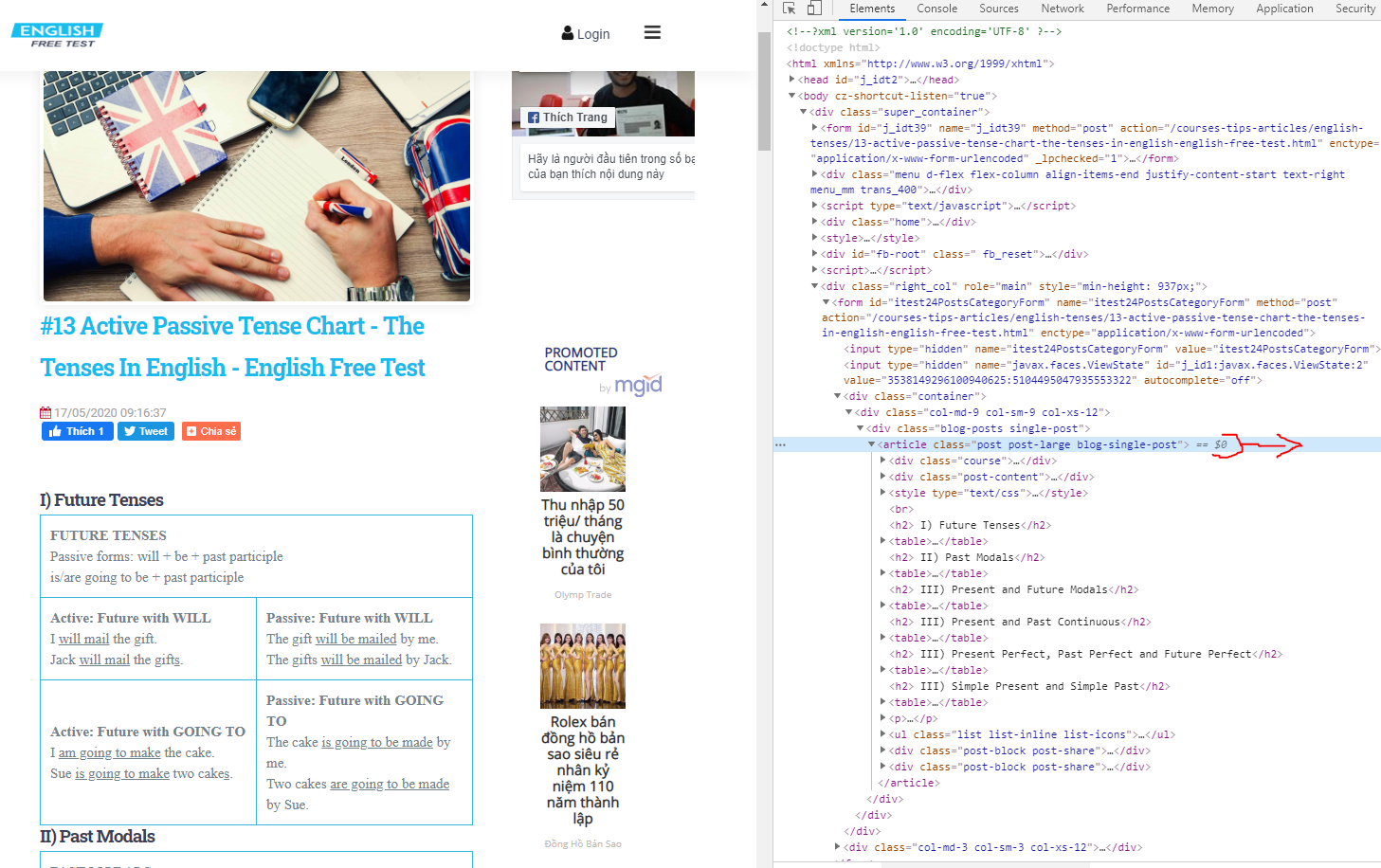
Ok vậy là đã phân tích xong. Giờ tiến hành code thôi.
2.2. Lấy danh sách các bài viết
Thông qua Jsoup thực hiện request tới link danh mục các bài viết ở đây tôi để thời gian timeout là 20s đây là khoảng thời gian chương trình chờ kết quả trả về từ website (tùy vào trang web cũng như nội dung dữ liệu mà bạn cần lấy mà xác định con số timeout cho phù hợp)
Sau khi trả về kết quả trả về thông qua phân tích đã thực hiện ở bước trên chúng ta lấy link danh sách các bài viết bằng việc duyệt các phần tử mà Jsoup đã lấy được
package com.webscraping;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/**
* NHT
*/
public class Demo {
public static void main(String[] args) {
String url = "https://englishfreetest.com/courses-tips-articles/english-tenses.html";
Document doc = null;
try {
doc = Jsoup
.connect(url)
.userAgent("Jsoup client")
.timeout(20000).get();
//lấy danh sách các thể <a> chứa bài viết từ kết quả trả về
Elements lstArticles = doc.select("div.post-content h2 a");
for (Element element : lstArticles) {
// Link bài viết nằm trong thuộc tính href của thẻ <a>
System.out.println("link:"+element.attr("href"));
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
kết quả trả về:
.PNG)
Lấy danh sách các bài viết
Duyệt danh sách các bài viết đã lấy được ở trên và với mỗi bài viết tiếp tục sử dụng Jsoup thực hiện request. Lấy dữ liệu trả về phân tích và lấy nội dung bài viết theo phân tích đã thực hiện ở trên
package com.webscraping;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/**
* NHT
*/
public class Demo {
public static void main(String[] args) {
String url = "https://englishfreetest.com/courses-tips-articles/english-tenses.html";
Document doc = null;
try {
doc = Jsoup
.connect(url)
.userAgent("Jsoup client")
.timeout(20000).get();
//lấy danh sách các thể <a> chứa bài viết từ kết quả trả về
Elements lstArticles = doc.select("div.post-content h2 a");
for (Element element : lstArticles) {
// Link bài viết nằm trong thuộc tính href của thẻ <a>
System.out.println("link:"+element.attr("href"));
doc = Jsoup
.connect(element.attr("href"))
.userAgent("Jsoup client")
.timeout(20000).get();
//Lấy nội dung bài viết
Elements article = doc.select("article.post");
// Ở đây tôi cần nội dung bài viết dạng html nên không cần phân tích tiếp nữa
System.out.println(article.get(0).html());
// Do something
//............................
//............................
//............................
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Thành quả
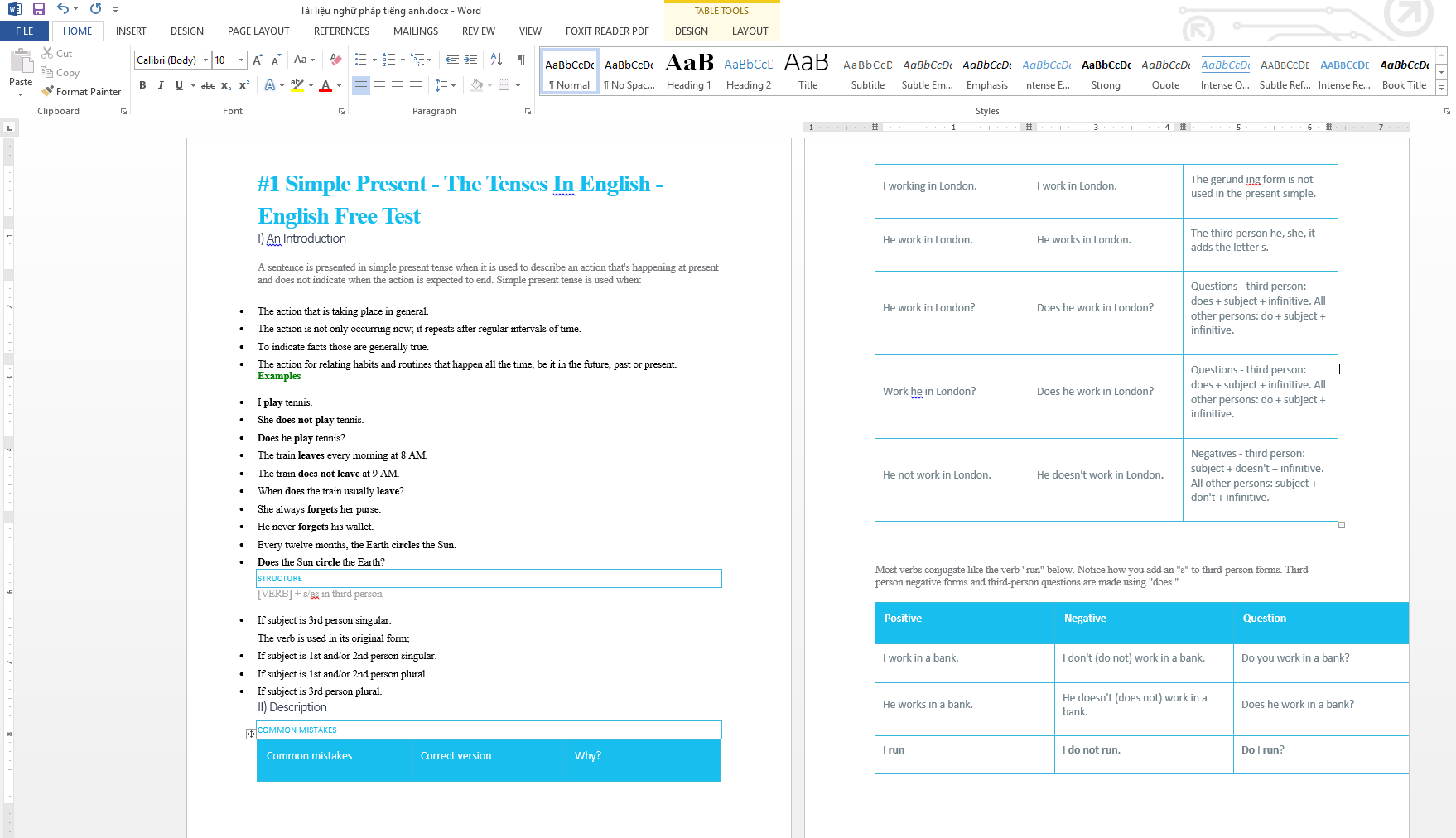
Tất nhiên để ra được file Word trên bạn cần code thêm cả phần tạo file word từ dữ liệu thu thập được nữa. Tuy nhiên do khuôn khổ bài viết chỉ là giới thiệu Web scraping với Java nên mình không để cập ở đây.
Một số chú ý:
- Đây chỉ là một ví dụ nho nhỏ để các bạn hiểu Web scraping với Java và cách thực hiện tuy nhiên khi một yêu cầu cần thống kê số lượng dữ liệu lớn, và lượng data phân tích nhiều bạn nên suy nghĩ đến việc dùng Thread để chia luồng và thực hiện đồng thời.
- Thử suy nghĩ viết dạng mở rộng để tạo thành một module khi cần lấy dữ liệu một site nào đó chỉ cần cấu hình ?
- Việc lấy dữ liệu của người khác suy cho cùng là không đúng nên hãy dùng nó vào các mục đích tốt đẹp nhé (ví dụ như là để thực hành kỹ năng code của mình)
Chúc các bạn thành công!
Post Comment