





Thuật Toán Đào Tạo Mạng Học Sâu Nhanh Gấp 15 Lần GPU

Tại hội nghị MLSys 2021, các nhà khoa học máy tính từ Đại học Rice đã giới thiệu một phần mềm trí tuệ nhân tạo (AI) có thể chạy trên bộ xử lý CPU phổ thông và đào tạo mạng học sâu nhanh hơn 15 lần so với các nền tảng chạy trên bộ xử lý đồ họa GPU.
Anshumali Shrivastava – Trợ lý giáo sư ngành Khoa học máy tính tại Trường Kỹ thuật Brown, trực thuộc đại học Rice, cho hay: Việc phải có một nguồn tài nguyên khổng lồ để đào tạo AI thực sự là rào cản rất lớn trong lĩnh vực này. Các công ty đang phải chi hàng triệu đô la mỗi tuần để đào tạo và fine-tune hệ thống AI của họ.

Anshumali Shrivastava là trợ lý giáo sư ngành Khoa học máy tính tại Đại học Rice. Nguồn: Jeff Fitlow/Đại học Rice
Mạng nơ-ron học sâu (Deep Neural Network) là một loại trí tuệ nhân tạo rất mạnh, có thể vượt trội hơn con người ở một số nhiệm vụ. Đào tạo mạng nơ-ron học sâu là một chuỗi các hoạt động nhân ma trận và đây là khối lượng công việc lý tưởng cho các đơn vị xử lý đồ họa (GPU). Tuy nhiên, chi phí sử dụng GPU cao hơn gần ba lần so với các đơn vị xử lý trung tâm đa năng (CPU).
Mọi tổ chức, đội ngũ nghiên cứu trên thế giới đang tìm hiểu và phát triển phần cứng và kiến trúc chuyên biệt mà có thể thúc đẩy nhân ma trận. Hơn nữa, bây giờ mọi người chỉ nói về những cấu trúc xếp chồng khối phần cứng-phần mềm chuyên biệt cho việc học sâu cụ thể, thay vì tiêu tốn tiền bạc vào việc phát triển một thuật toán đắt tiền hay cố gắng tối ưu hóa hệ thống.
Vào năm 2019, Shrivastava và nhóm của anh ấy đã đúc kết lại quá trình đào tạo mạng nơ-ron học sâu về thành một bài toán tìm kiếm (search problem) có thể được giải quyết bằng bảng băm (hash table). “Công cụ học sâu tiểu tuyến tính” (Sub-linear deep learning engine – SLIDE) của họ được thiết kế đặc biệt để chạy trên các CPU phổ thông.
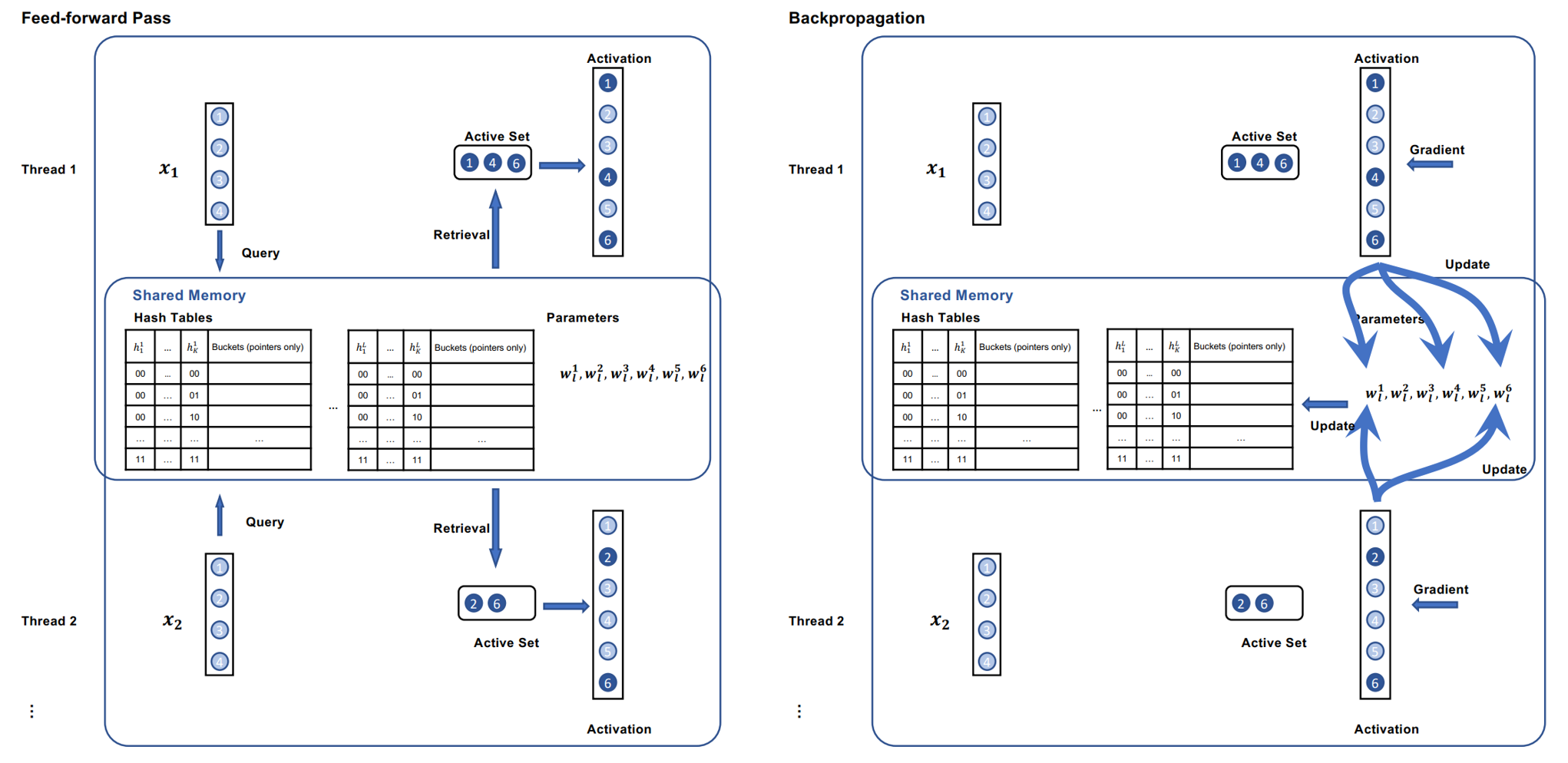
Hình 1. Minh họa cách feed-forward và backward pass bằng bài toán tìm kiếm và áp dụng bảng băm. Hai luồng (thread 1 và thread 2) đang xử lý song song hai đối tượng dữ liệu x1 và x2 với bảng băm Locality Sensitive Hashing (LSH) và các tham số trong không gian bộ nhớ chung.
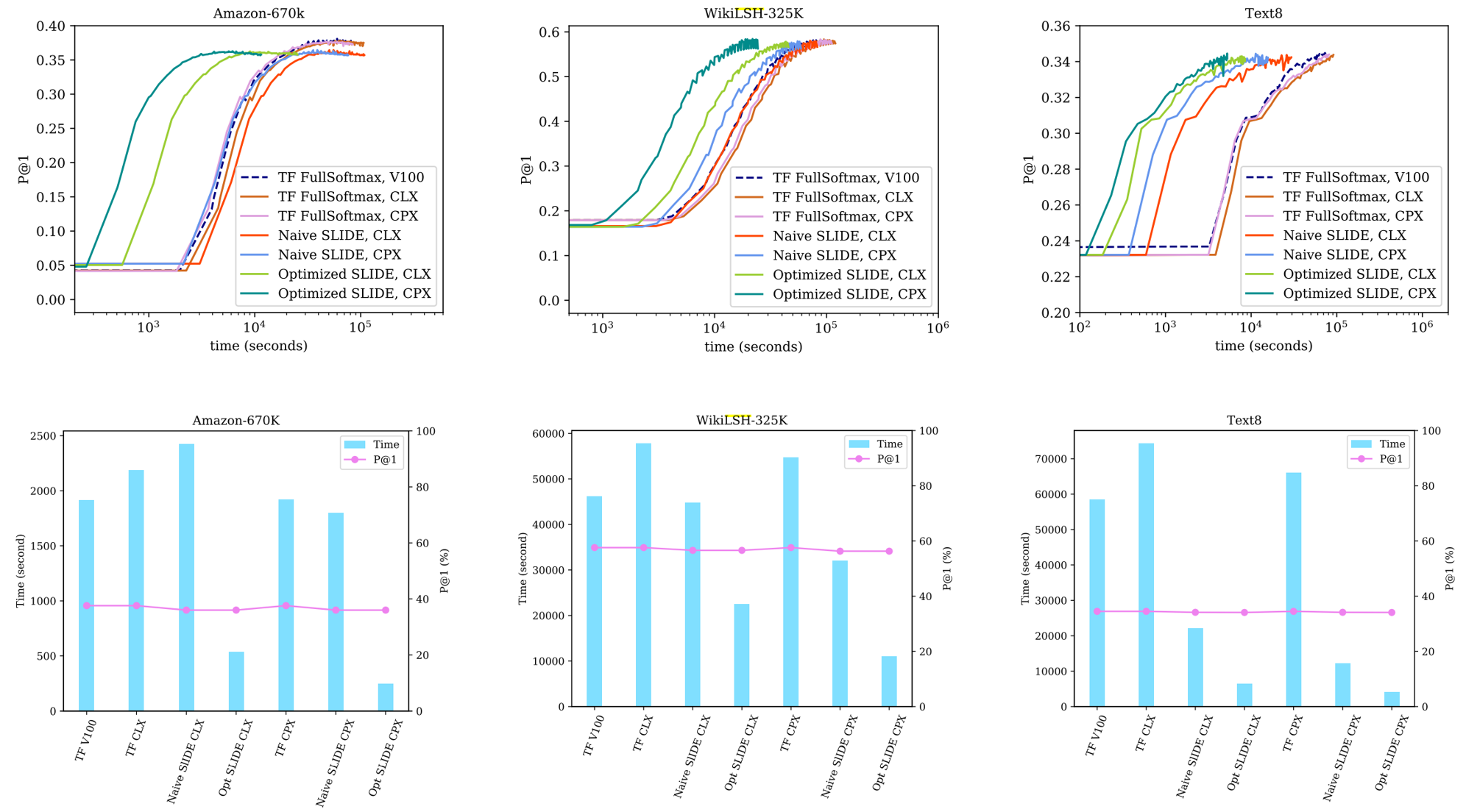
Hình 2. So sánh SLIDE được tối ưu hóa (Opt SLIDE CPX) trên hai CPU Intel mới (CLX và CPX) với SLIDE cổ điển (Naïve SLIDE CPX) trên cùng một CPU và Tensorflow full-softmax trên V100 và CLX/CPX.
Hàng trên: Các biểu đồ hội tụ cho tất cả các phương pháp trên tất cả các tập dữ liệu. Các trục y là Độ chính xác (Precision@1) và trục x biểu thị thời gian luyện tập theo thang logarit. Trong tất cả các lô hội tụ SLIDE được tối ưu hóa trên CPX và CLX (được hiển thị bằng màu xanh lá cây đậm và nhạt tương ứng) tốt hơn tất cả các đường cơ sở khác với tỷ suất vượt trội đáng kể.
Hàng dưới: Hiển thị các biểu đồ thanh trong đó trục trái y đề cập đến thời gian đào tạo trung bình trên mỗi kỷ nguyên và trục y phải đề cập đến Độ chính xác (P@1). Các biểu đồ cột cho thấy, SLIDE được tối ưu hóa trên CPX và CLX (được hiển thị là Opt SLIDE) hoạt động tốt hơn các đường cơ sở khác về mặt thời gian luyện tập trong khi vẫn duy trì độ chính xác khá gần với full-softmax, thể hiện qua Độ chính xác (P@1) được hiển thị bằng đường màu hồng.
Cùng với các cộng tác viên của Intel, Shrivastava đã chứng minh rằng, SLIDE có thể hoạt động tốt hơn đào tạo dựa trên bộ xử lý GPU khi họ công bố nó tại hội thảo MLSys 2020. Bài nghiên cứu được trình bày tại MLSys 2021 tìm hiểu xem: Liệu có thể cải thiện hiệu suất của SLIDE bằng các bộ tăng tốc tối ưu hóa bộ nhớ và vector hóa trong các CPU hiện đại hay không?
Đồng tác giả nghiên cứu và một sinh viên tốt nghiệp Đại học Rice, Shabnam Dagahani, tin rằng, cấu trúc tăng tốc dựa trên bảng băm đã vượt trội hơn GPU, nhưng chính bản thân CPU cũng đang phát triển rất mạnh mẽ. Nhóm của họ đã tận dụng những đổi mới đó để đưa SLIDE đi xa hơn nữa, cho thấy rằng, nếu không bắt buộc phải sử dụng phép nhân ma trận, chúng ta có thể tận dụng sức mạnh trong các CPU hiện đại và đào tạo các mô hình AI nhanh hơn từ 4 đến 15 lần so với các giải pháp phần cứng chuyên dụng nhất. Trên thực tế, CPU vẫn là phần cứng phổ biến nhất trong máy tính. Vậy nên, việc phát triển cho CPU phù hợp và hiệu quả hơn với khối lượng công việc AI đem lại rất nhiều lợi ích cho người dùng phổ thông lẫn các công ty.
Bạn đọc có thể xem thêm link bài báo tại: https://arxiv.org/pdf/2103.10891.pdf
Github của SLIDE với hướng dẫn sử dụng chi tiết: https://github.com/RUSH-LAB/SLIDE
Post Comment