





Spark là gì?

Hầu hết các giải pháp phân tích dữ liệu đòi hỏi dữ liệu phải được truy cập và đưa vào bộ nhớ trước khi các nhiệm vụ xử lý dữ liệu có thể được thực hiện. Khi tập dữ liệu đang được phân tích lớn đến mức vượt quá giới hạn bộ nhớ truy cập ngẫu nhiên (RAM) của máy tính đang sử dụng, phân tích trở nên bất khả thi
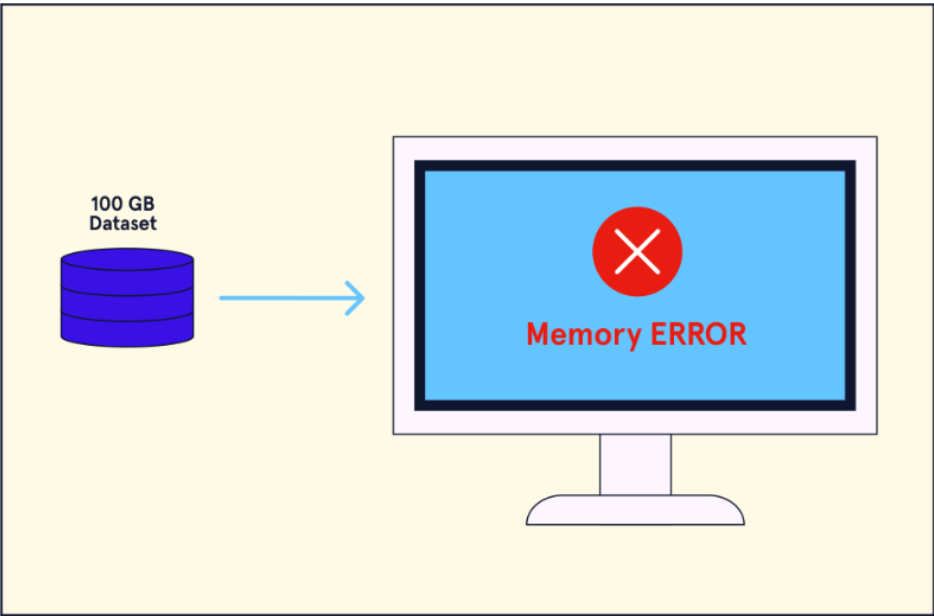
Để giải quyết vấn đề lưu trữ big data, chúng ta có thể chia tập dữ liệu và lưu trữ nó trên nhiều máy tính. Khung làm việc này được biết đến với tên gọi hệ thống tệp phân tán. Một lựa chọn phổ biến là Hadoop Distributed File System (HDFS), cho phép chia tập dữ liệu và lưu trữ nó trên nhiều node làm việc trong một cụm.
MapReduce là một khung làm việc tính toán cho việc phân tích các tập dữ liệu được lưu trữ trên một hệ thống tệp phân tán như HDFS. MapReduce là một phương pháp disk-oriented, có nghĩa là MapReduce ghi dữ liệu vào đĩa bằng các bước trung gian của phân tích. Mặc dù phương pháp này cho phép chúng ta xử lý dữ liệu được lưu trữ trên HDFS, nó vẫn là một quá trình chậm chạp để phân tích các tập dữ liệu lớn hơn.
Apache Spark và PySpark
Khi nhu cầu xử lý big data đã tăng lên, công nghệ mới đã được phát triển. Spark là một công cụ phân tích được phát triển ban đầu tại Đại học California, Berkeley và sau đó được quyên góp cho tổ chức open-sourced Apache Software Foundation. Spark được thiết kế như một giải pháp cho việc xử lý các tập big data và được phát triển đặc biệt để xây dựng các đường dây dữ liệu cho ứng dụng machine learning. Tương tự như MapReduce, Spark không có hệ thống lưu trữ tệp riêng và được thiết kế để sử dụng với hệ thống tệp phân tán như HDFS. Tuy nhiên, Spark cũng có thể chạy trên một node (máy tính đơn) trong chế độ độc lập với một tập dữ liệu không phân tán.
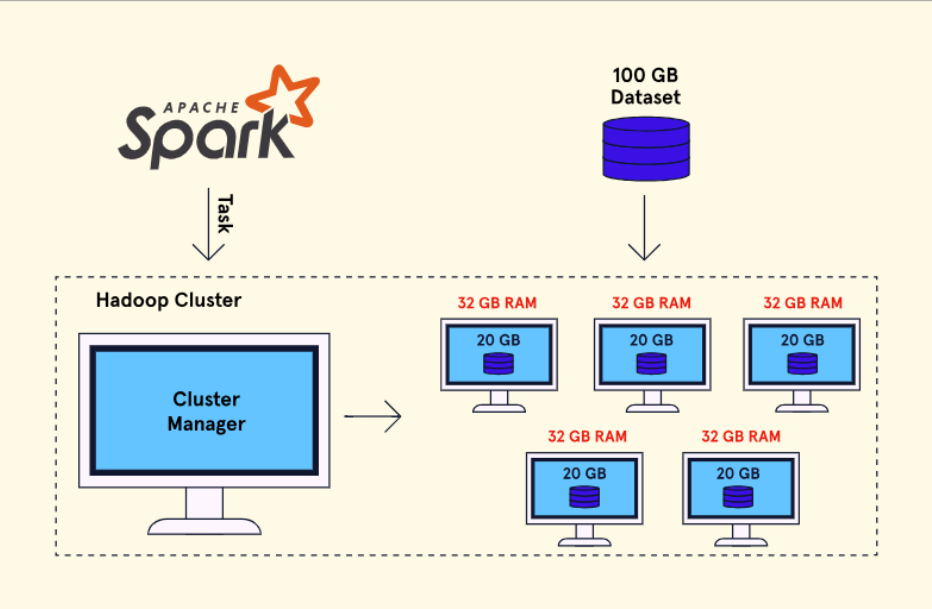
Spark sử dụng RAM của mỗi cluster node một cách trơn tru, khai thác được sức mạnh của nhiều máy tính. Các ứng dụng Spark thực hiện phân tích nhanh gấp đến 100 lần so với MapReduce vì Spark lưu trữ dữ liệu và bảng trung gian trong RAM thay vì ghi chúng vào đĩa. Tuy nhiên, khi tập dữ liệu trở nên lớn hơn, ưu điểm của việc sử dụng RAM giảm và có thể hoàn toàn biến mất.
PySpark là gì?
Spark ban đầu được phát triển bằng Scala (một ngôn ngữ lập trình hướng đối tượng và hàm). Điều này gây ra thêm một rào cản cho người dùng khi học cách viết code trong Scala để làm việc với Spark. PySpark là một API được phát triển để giảm thiểu rào cản học này bằng cách cho phép các lập trình viên viết cú pháp Python để xây dựng các ứng dụng Spark. Cũng có các API cho Java và R.
Cách Spark Hoạt Động
Bây giờ khi chúng ta đã hiểu về Spark một cách tổng quan, hãy khám phá cách một ứng dụng Spark hoạt động một cách chi tiết hơn. Trình điều khiển Spark là đầu vào điểm nhập của một ứng dụng Spark và được sử dụng để tạo một phiên Spark. Chương trình điều khiển giao tiếp với quản lý cụm để tạo các tập dữ liệu phân tán bền vững (RDDs). Để tạo một RDD, dữ liệu được chia nhỏ và phân phối trên các node làm việc trong một cụm. Bản sao của RDD trên các node đảm bảo rằng RDD là chống lỗi, do đó thông tin có thể được khôi phục trong trường hợp xảy ra sự cố. Hai loại hoạt động có thể được thực hiện trên RDDs:
- Các biến đổi điều chỉnh RDD trên cụm.
- Các hành động trả về một tính toán trở lại chương trình điều khiển chính.
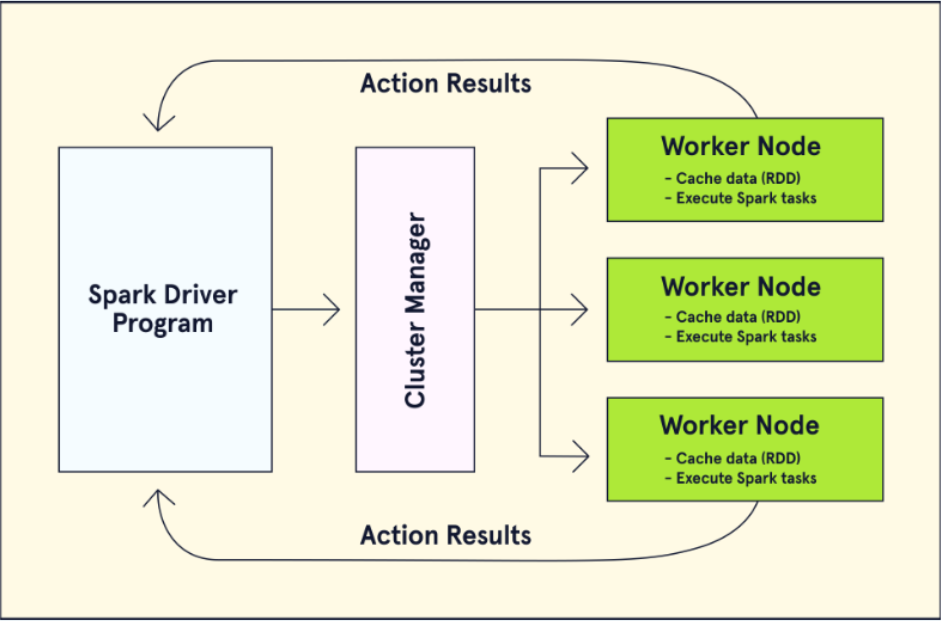
Cluster manager xác định các tài nguyên mà ứng dụng Spark yêu cầu và gán một số lượng cụ thể các node làm việc như thực thi viên để xử lý việc xử lý của RDDs. Spark có thể chạy trên ba cụm quản lý khác nhau, bao gồm YARN của Hadoop và Apache Mesos.
Các mô-đun Spark
Chương trình điều khiển là nhân tố cốt lõi của ứng dụng Spark, nhưng cũng có các mô-đun đã được phát triển để tăng cường tính hữu ích của Spark. Các mô-đun này bao gồm:
Spark SQL: một API chuyển đổi các truy vấn SQL và hành động thành các tác vụ Spark được phân phối bởi quản lý cụm. Điều này cho phép tích hợp các SQL hiện có mà không cần phát triển lại mã và kiểm tra sau đó được yêu cầu để kiểm soát chất lượng.- Spark Streaming: một giải pháp cho việc xử lý luồng dữ liệu trực tiếp tạo ra một luồng rời rạc (Dstream) của các lô RDD.
- MLlib và ML: các mô-đun học máy để thiết kế các đường ống được sử dụng cho kỹ thuật chế biến đặc trưng và đào tạo thuật toán. ML là cải tiến dựa trên DataFrame so với mô-đun MLlib gốc.
- GraphX: một giải pháp đồ thị mạnh mẽ cho Spark. Hơn chỉ là trực quan hóa dữ liệu, API này chuyển đổi RDDs thành đồ thị phân tán bền vững (RDPGs) sử dụng thuộc tính đỉnh và cạnh cho phân tích dữ liệu liên quan.
Post Comment