





Render 3D Nhanh Trên QEMU

Dạo này có yêu cầu case study về virtualization nên tôi chợt nhớ ra có một con prototype khá thực dụng mà tôi làm từ đời Tống. Chẳng may, à không rất may là giờ nó vẫn còn đúng, tình hình chả thay đổi gì cả. Bài học rút ra là làm gì cũng cần phải để lại di sản. Nhiều khi bạn quay tay ra được một cái gì đấy cũng rất kinh, hoặc kinh vừa vừa thì cũng nên tạo tài liệu để lại cho đời, đừng làm xong chỉ để đắp chiếu, mà hãy đắp chiếu nó bằng một cái blog.
Hardware virtualization là gì?
Cái này nghe thì ghê gớm chứ thực ra dễ hiểu bỏ BU (business unit). Đơn giản hardware là hardware, còn virtualization là virtualization. Ah nhầm, virtualization là ảo hoá. Tức là ta trick một thằng nào đấy để nó nghĩ là nó có riêng cho mình một cái hardware trong khi thực ra là không. Giống kiểu strength virtualization, hay dịch nôm thì ATSM là khi một thằng nghĩ nó mạnh như vừa cắn rau chân vịt trong khi thực ra đấy chỉ là cỏ thôi. 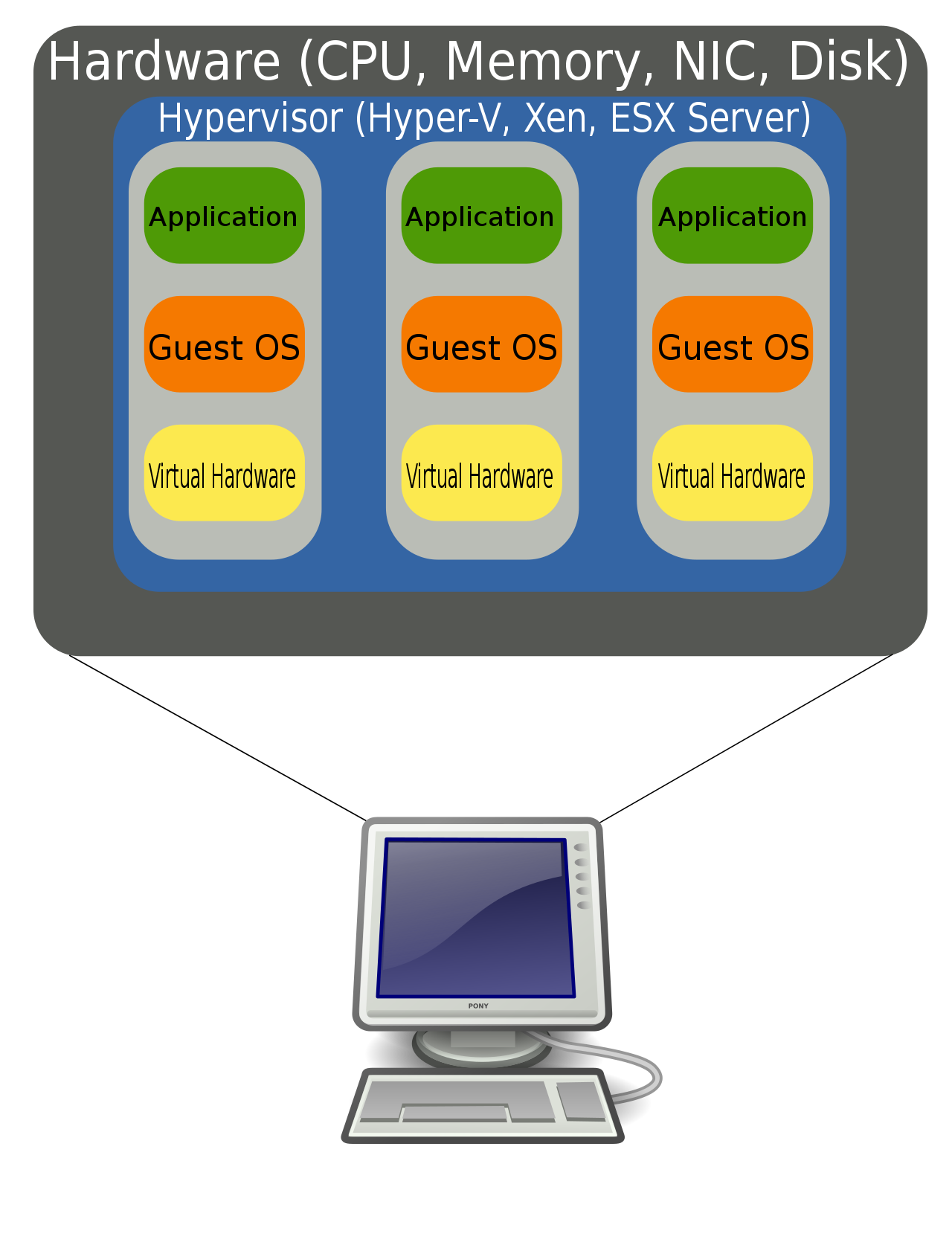
Hardware virtualization (nguồn: wikipedia)
Phần lớn các ứng dụng khi được chạy trên môi trường ảo hoá thời buổi bây giờ đều có hiệu năng khá tốt. Lý do là ảo hoá phần cứng được tích hợp luôn vào thiết kế của các CPU hiện đại. Cốt lõi của ảo hoá là khối quản lý memory (MMU) thuộc CPU. Như các bạn đã biết, hardware giao tiếp với software (driver) thông qua các register được map vào một vùng nhớ xác định. Tức là khi ta ảo hoá thì ta cần biết được khi nào software đọc / ghi vào register và với giá trị là gì để giả lập các hành vi tương ứng của hardware.
Tức là với dòng code kiểu như thế này:
int *num; /*...*/ *num = 100;Vì ta không thể biết cái con trỏ num kia có phải đang trỏ đến một register hay không. Cho nên để ảo hoá được thì thường ta phải translate đoạn code trên thành kiểu như thế này:
int *num; /*...*/
if (num == REGISTER_X) {
virt_hw_on_num_write(100);
} else {
*num = 100;
}
Đại khái thế, cứ chỗ nào đọc ghi vào memory thì virtual machine đều phải chèn thêm code để biết liệu software nó có đang định chơi với hardware hay chỉ đọc ghi vào RAM. Dẫn đến chương trình được ảo hoá sẽ chạy rất chậm. Tuy nhiên nếu MMU có hỗ trợ virtualization thì ta có thể yêu cầu MMU trap những lệnh đọc ghi vào địa chỉ của các thanh ghi mà ta muốn. Như vậy code không có gì thay đổi, MMU sẽ tự động báo thông qua interrupt.
Thế tại sao vẫn chậm?
QEMU là một hardware emulator thường được sử dụng trong automotive. Và khi được dùng để chạy những ứng dụng có liên quan đến vẽ vời thì nó chạy siêu chậm (0.5 FPS). Theo quảng cáo thì QEMU có binary translator, tức là nó có thể dịch mã máy từ ARMvX sang x86_64, tức là nó không hề thông dịch. Ngoài ra khi sử dụng trên Linux thì nó sẽ chơi với KVM (một con hypervisor ở kernel-mode) để trap những lệnh đọc ghi vào register qua MMU.
Để hiểu rõ hơn tại sao chậm ta cần hiểu nguyên tắc thiết kế của CPU. CPU dịch nôm là bộ xử lý trung tâm, nhiệm vụ chính của nó là xử lý logic. Tức là kiểu nếu thế này thì thế kia, và nó được tối ưu cho riêng việc đấy. Nếu ông nào còn nhớ thì có 2 con bug về kiến trúc của CPU là Meltdown & Spectre, lợi dụng các tối ưu liên quan đến if-else (branch predictor) và cache latency để khai thác thông tin. Thì để fix cái lỗi đấy ta phải by-pass / turn off các tối ưu trên khiến cho tốc độ thực thi cũng theo đó chậm như rùa luôn.
Còn mấy trò vẽ vời thì nó lại ngược lại, graphic pipeline thuần tuý nặng về tính toán số học. Kiểu ta có một cái hình tròn đen trên nền trắng thì việc vẽ nó ra là xác định xem pixel nào cần đen, pixel nào cần trắng, dựa trên khoảng cách từ pixel đến tâm hình tròn. Giả dụ cái nền trắng của ta kích thước là 800×600 thì ta cần tính 800×600 lần. Cái hay ho là từng pixel đều được tính độc lập, không phụ thuộc vào kết quả của những pixel khác nên nếu ta có 800×600 core thì ta có thể giải bài toán này trong vòng 1 cycle.
GPU được thiết kế để giải bài toán trên, core của GPU thuần tuý phục vụ tính toán số học, không có những tính năng thừa thãi của CPU như branching optimization hay interrupt handler. Nhờ thiết kế tối giản, tập trung vào một mục đích duy nhất là tính toán cho nên chi phí tạo ra một core của GPU rất rẻ và ta có thể có hàng ngàn core. Hiệu suất tính toán tốt hơn nhiều trên chi phí đầu tư nếu gặp bài toán phù hợp. Đây cũng là lý do vì sao khi bài toán mới như AI hay đào bitcoin xuất hiện thì mấy ông trùm sản xuất GPU một bước lên mây.
Quay về bài toán vẽ vời trên QEMU, thì nó như thế này:
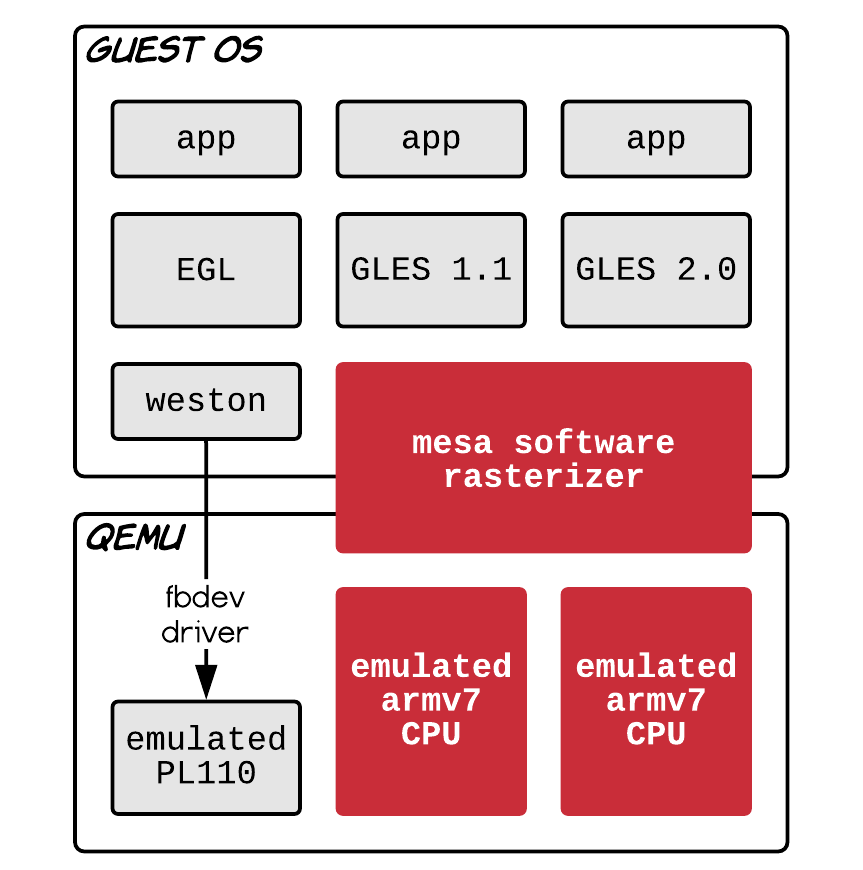
Original (slow)
Nhìn vào cái cục màu đỏ ta thấy là thực ra guest OS nó dek nhìn thấy cái GPU đâu cả. Cho nên nó đang vẽ hoàn toàn bằng CPU. Vẽ vời đơn giản thì không sao chứ vẽ nhiều xong lại còn 3D, shader các kiểu thì có chạy nhanh vào mắt. Cho nên vấn đề không phải là QEMU tính toán overhead nhiều, mà do chưa tận dụng được GPU. Vẽ bằng CPU thì chả ảo hoá nó cũng chậm thôi.
Giải pháp EMUGL
OK, bây giờ biết là cần dùng GPU rồi. Một hướng tiếp cận khá hay của Android Emulator là tìm cách translate các API liên quan đến vẽ vời (GLES) sang host (OpenGL). Cách làm này có ưu điểm là tương đối portable. Nó by-pass hoàn toàn graphic stack của guest (MESA etc.), miễn ứng dụng của ta sử dụng GLES là nó chơi được hết. Kể cả là guest có là RTOS, QNX, AUTOSAR bloh blah.
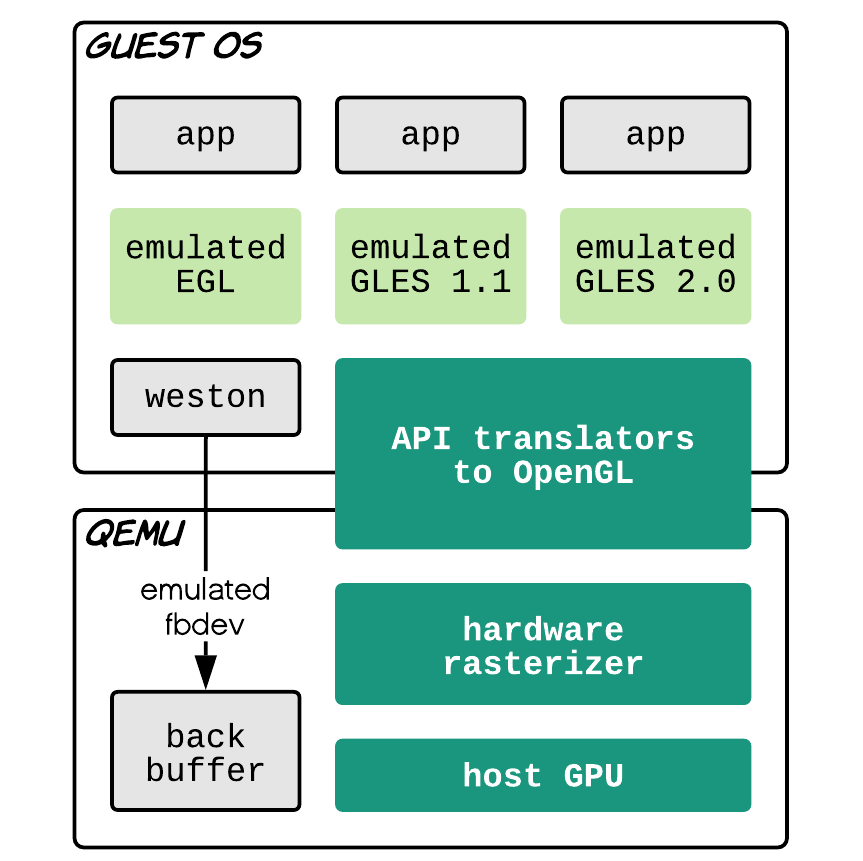
EMUGL: borrowed from Android Emulator
Tuy nhiên trong quá trình làm demo với QEMU và guest là Linux thì sẽ có một vài khó khăn như Window Compositor trên Linux mà đội automotive hay dùng lại là Wayland. Cho nên EGL translator (là thằng chơi với compositor) sẽ phải viết lại để theo Wayland (chứ không phải Android). Ngoài ra thì vì vẽ vời trên GPU của host cho nên kết quả nó nằm mẹ trên đấy luôn. Muốn phệt nó sang con emulated PL110 của QEMU thì ta phải đi đường vòng là read-back nó ngược lại về CPU làm ảnh hưởng đến hiệu năng. Thay vào đó ta sửa lại thằng Weston để nó không dùng fbdev nữa mà vẽ lên một cái emulated-fbdev với output là cái back buffer đang nằm sẵn trên GPU.
Kết quả thì rất khả quan, từ 0.5 FPS lên dc 70 FPS trên Macbook Pro ngày ấy.
Về source code thì tôi … err không tìm thấy, sorry vì nó lâu quá rồi.
Giải pháp paravirtualized GPU
Một cách khác là emulate phần dưới cùng của graphic stack (GPU driver).
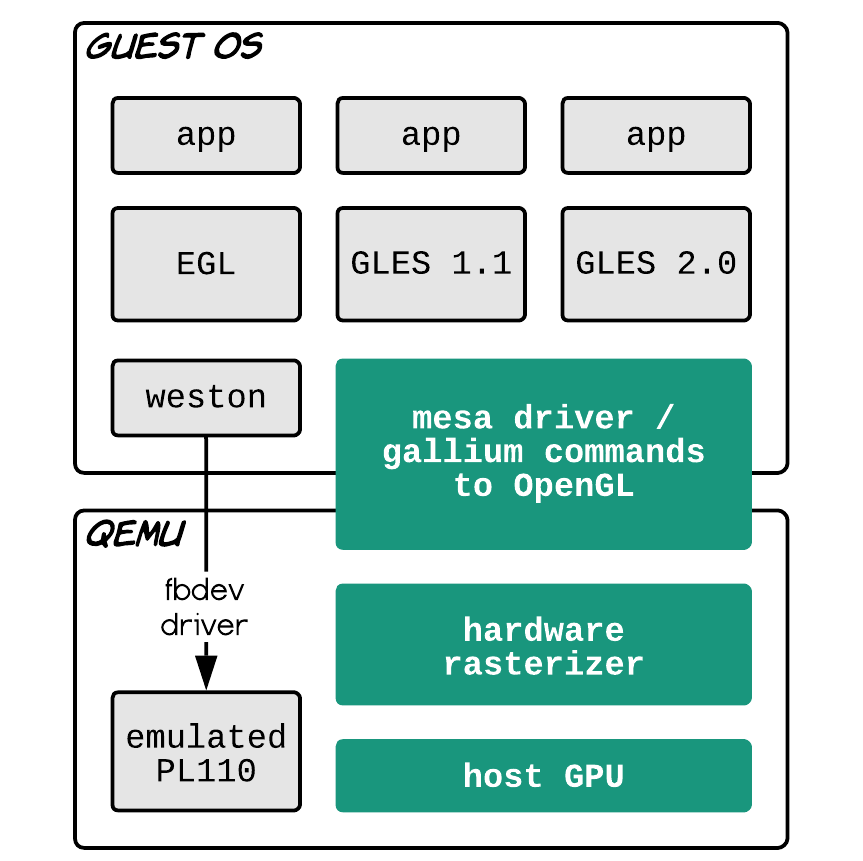
Virgil 3D: paravirtualized GPU
Bọn graphic stack trên Linux (MESA) nó có một cái tầng intermediate representation là Gallium3D. Nhiệm vụ của thằng này là decouple tầng API ra khỏi hardware. Như ta đã biết thì có rất nhiều thể loại graphic API như OpenGL, GLES, DirectX, Vulkan, Metal etc. Mỗi thằng GPU vendor mà đi support tất cả cái mớ đấy thì rất tốn kém. Thay vào đó MESA sẽ abstract phần cứng khỏi API, tất cả các API trên đều output ra thành Gallium3D representation, kể cả shader luôn. Như kiểu từ Java thì thành JVM bytecode ý, chứ không phải assembly nhá. Còn thằng GPU vendor thì việc của nó bây giờ đơn giản là viết cái driver để từ Gallium3D ra hardware thôi.
Thì lợi dụng kiến trúc trên, ta viết một con driver cho MESA để từ Gallium3D ra thành OpenGL API và GLSL shader trên host. Ưu điểm là sau khi có con driver này rồi thì tầng app có thể sử dụng mọi thể loại API mà MESA cung cấp chứ không chỉ riêng GLES. Tuy nhiên nhược điểm là nó dính vào MESA, cho nên guest không phải Linux thì khỏi dùng. Ngoài ra cái này cũng cần kernel khá mới, khả năng phải back-port một số thứ nếu guest đang dùng kernel cũ.
Tham khảo
G.Yakiro
Post Comment