





Nhập môn Amazon EMR

Giới thiệu
Amazon EMR là một nền tảng cụm dữ liệu lớn được quản lý để chạy các khung công việc dữ liệu lớn. Nó được thiết kế để sử dụng các khung công việc như Apache Spark để xử lý lượng dữ liệu lớn (quy mô petabyte). Nó cho phép bạn phát triển ứng dụng trong EMR Studio bằng cách sử dụng các công cụ như EMR notebooks. Nếu bạn quan tâm tìm hiểu về Amazon EMR, hướng dẫn này sẽ giúp bạn có một khởi đầu cơ bản trên nền tảng này.
Lưu ý: Amazon EMR không phải là một dịch vụ miễn phí. Để biết thông tin về giá cả, bạn có thể truy cập trang web này: aws.amazon.com
Thiết lập Amazon EMR
Có một số bước bạn cần hoàn thành để bắt đầu sử dụng Amazon EMR.
- Trước tiên, bạn cần có một tài khoản AWS. Nếu bạn chưa có, bạn có thể đăng ký tại aws.amazon.com.
Lưu ý: Trong khi AWS có một mức miễn phí, Amazon EMR không phải là một dịch vụ miễn phí.
- Khi thiết lập AWS, việc tạo một người dùng quản trị để thực hiện các nhiệm vụ hàng ngày như làm việc với Amazon EMR là một thói quen tốt, để bạn không thực hiện tất cả mọi thứ bằng tài khoản gốc.
- Nếu bạn muốn kết nối với các cụm Amazon EMR qua SSH, bạn cần tạo một cặp khóa để xác thực. Hướng dẫn chi tiết có tại aws.amazon.com.
Lưu ý: Bước cuối cùng này không cần thiết cho hướng dẫn này.
Thiết Lập Một Ứng Dụng
Để xử lý dữ liệu bằng Amazon EMR, bạn cần tải dữ liệu và các hướng dẫn để xử lý nó. Trong hướng dẫn này, bạn sẽ lưu trữ chúng trong một bucket Amazon S3. Để tạo bucket, đăng nhập vào Bảng điều khiển quản lý AWS và mở bảng điều khiển Amazon S3 . Mở bảng điều hướng bên trái và nhấp vào “Buckets” (Thùng).
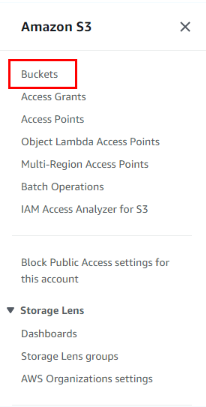
Việc này sẽ đưa bạn đến danh sách các bucket có sẵn trong tài khoản AWS của bạn. Trên màn hình này, nhấp vào nút có nhãn “Create Bucket” (Tạo Bucket).
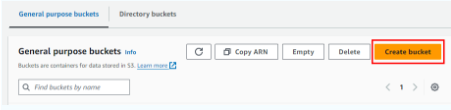
Việc này sẽ đưa bạn đến trang các tùy chọn cho bucket mới của bạn. Bạn sẽ được yêu cầu chọn một khu vực và đặt tên cho bucket. Chọn một khu vực gần bạn và đặt tên bucket ví dụ như “[tên của bạn]-my-emr-test” (ví dụ: “john-my-emr-test”). Bạn có thể để nguyên các giá trị mặc định cho các thiết lập khác trên trang này. Ở phần cuối trang, nhấp vào “Create Bucket” (Tạo Bucket). Bạn sẽ được chuyển trở lại danh sách các bucket với bucket mới của bạn được liệt kê.
Bây giờ bạn đã có một vị trí để lưu trữ dữ liệu và ứng dụng của bạn.
Ghi chú: Nếu không có gì xảy ra khi bạn nhấp vào “Create Bucket” (Tạo Bucket), có thể có xung đột tên. Cuộn lên và xem xem có cảnh báo bên cạnh hộp văn bản tên hay không. Nếu có, thay đổi tên để làm cho nó trở thành duy nhất.
Để tải tệp lên bucket của bạn, nhấp vào tên bucket trong danh sách bucket. Bạn sẽ được chuyển đến trang chủ của bucket, và sẽ có một nút “Upload” (Tải lên) ở bên phải. Bạn sẽ nhấp vào nút này để tải lên tệp của bạn.
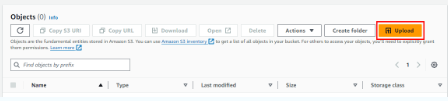
Trước khi làm điều này, bạn cần có dữ liệu và một ứng dụng để truy cập nó. Về dữ liệu, chúng ta sẽ tải một bộ dữ liệu CSV. Để có một bộ dữ liệu cho hướng dẫn này, hãy truy cập trang Kaggle và tải xuống bộ dữ liệu Google Play Store Apps. (Nếu bạn chưa có tài khoản Kaggle, bạn sẽ phải đăng ký. Miễn phí.) Sau khi tải xuống file archive.zip, giải nén nó thành ba tệp. Tệp bạn sẽ sử dụng là googleplaystore.csv. Sau khi bạn có tệp này trên máy tính cá nhân, bạn có thể tải nó lên bucket của bạn.
Nhấp vào “Upload” (Tải lên) trên màn hình chủ của bucket sẽ đưa bạn đến một trang tải lên nơi bạn có thể thêm tệp và tải lên chúng. Nhấp vào “Add Files” (Thêm Tệp) và chọn googleplaystore.csv từ nơi bạn đã lưu nó.
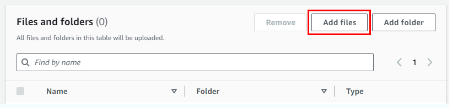
Sau khi thêm tệp, cuộn xuống dưới cùng của trang và nhấp vào “Upload” (Tải lên). Tệp CSV sẽ được tải lên bucket của bạn.
Tiếp theo, chúng ta cần một ứng dụng, một cái gì đó mà cụm có thể sử dụng để xử lý dữ liệu. Để làm điều này, chúng ta sẽ sử dụng một tập lệnh Python sử dụng PySpark. Dưới đây là một tập lệnh mẫu để sử dụng trong hướng dẫn này:
import argparse
from pyspark.sql import SparkSession
def get_top_ten_categories(source, output):
"""
Process Google Play Store data and return the top 10 categories by average rating.
source: The URI of the Play Store dataset, 's3://MY-BUCKET-NAME/googleplaystore.csv'
output: The URI where output is written, 's3://MY-BUCKET-NAME/output'
"""
with SparkSession.builder.appName("Get Top Ten Categories").getOrCreate() as spark:
# Load CSV data
if source is not None:
google_df = spark.read.option("header","true").csv(source)
# Create an in-memory DataFrame to query
google_df.createOrReplaceTempView("google_play_store")
# Create a DataFrame of our query
top_ten = spark.sql("""SELECT Category, AVG(Rating) AS avg_rating
FROM google_play_store
WHERE NOT Rating = "NaN" AND Rating <= 5
GROUP BY Category
ORDER BY avg_rating DESC LIMIT 10""")
# Write output
top_ten.write.option("header","true").mode("overwrite").csv(output)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--source')
parser.add_argument('--output')
args = parser.parse_args()
get_top_ten_categories(args.source, args.output)
Lưu trữ tệp lệnh dưới tên google_top_ten.py và sau đó tải lên thư mục của bạn vào bucket giống như bạn đã làm với tệp googleplaystore.csv.
Khi cả hai tệp đều đã được đặt vào đúng vị trí, bạn đã sẵn sàng để khởi chạy cụm của mình.
Khởi chạy Cụm
Để khởi chạy một cụm, bạn cần đăng nhập vào bảng điều khiển quản lý AWS. Sau đó, bạn cần mở Bảng điều khiển Amazon EMR. Trên menu bên trái trong Bảng điều khiển Amazon EMR, bạn chọn “Clusters” nếu chưa được chọn. Điều này sẽ mở một trang liệt kê các cụm EMR của bạn và bên phải sẽ là một nút “Tạo Cụm”.
Post Comment