





Lưu trữ và tính toán Big data

Những thách thức với Big data
Mỗi ngày, hơn 2,5 tỉ tỉ byte dữ liệu được tạo ra. Đó là số 2,5 với 18 số 0 sau đó! Từ dữ liệu giao dịch bán hàng đến các thiết bị Internet of Things (IoT), các nguồn dữ liệu ngày càng tăng về cả kích thước và tốc độ. Khi nghĩ về quy mô lớn của dữ liệu, chúng ta có thể tự hỏi: tất cả những dữ liệu này được lưu trữ ở đâu? Và làm thế nào để chúng ta có đủ sức mạnh máy tính để xử lý chúng?
Theo truyền thống, chúng ta có thể xem một tập dữ liệu cơ bản như một bảng trong Excel hoặc một ứng dụng tương đương. Những giải pháp tiêu chuẩn này đòi hỏi chúng ta kéo một tập dữ liệu đầy đủ vào bộ nhớ trên một máy tính xử lý duy nhất. Khi một bảng dữ liệu trở nên rất lớn, nó sẽ vượt quá bộ nhớ truy cập ngẫu nhiên (RAM) có sẵn để tính toán và entit đó sẽ bị sập hoặc mất quá nhiều thời gian để xử lý, làm cho phân tích trở nên không thể. Do đó, chúng ta cần tìm cách lưu trữ và xử lý dữ liệu lớn này một cách thay thế!
Lưu trữ Big data
Một giải pháp phổ biến cho các tập dữ liệu lớn là một hệ thống tệp phân tán trên mạng phần cứng gọi là một Cluster. Cluster là một nhóm của một số máy gọi là nodes, với một cluster manager node và nhiều worker nodes khác.
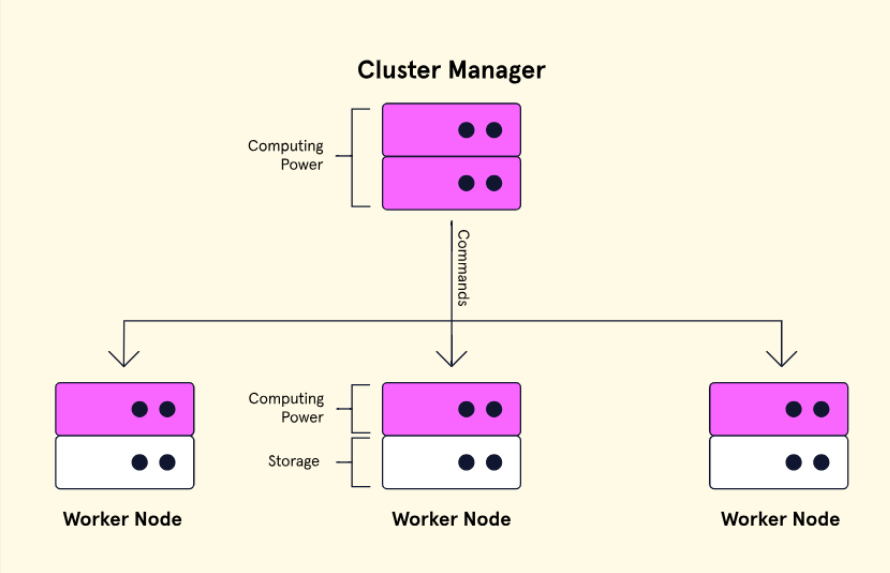
Người quản lý cluster quản lý các tài nguyên và gửi các lệnh đến các node làm việc lưu trữ dữ liệu. Dữ liệu được lưu trên các node làm việc được sao chép nhiều lần để chống lại sự cố. Điều này cho phép truy cập vào toàn bộ tập dữ liệu ngay cả khi một trong những node làm việc bị ngừng hoạt động. Loại hệ thống lưu trữ tệp này cũng dễ dàng và có thể mở rộng vô hạn, vì các node làm việc bổ sung có thể được thêm vào vô hạn.
Hệ thống Tệp Phân Tán Hadoop
Một trong những framework phổ biến được sử dụng cho hệ thống cluster được gọi là Hệ thống Tệp Phân Tán Hadoop (HDFS), là một phần của một bộ công cụ được phân phối bởi Apache. HDFS được thiết kế để lưu trữ lượng lớn dữ liệu để được xử lý bằng một framework khác gọi là MapReduce. Tuy nhiên, việc triển khai một hệ thống tệp phân tán như vậy đòi hỏi một cấu hình phần cứng cụ thể có thể là một rào cản chi phí đối với nhiều công ty. Vì lí do này, HDFS được lưu trữ trên đám mây là một giải pháp phổ biến. Microsoft Azure và Amazon Web Services (AWS) cung cấp các giải pháp HDFS dựa trên đám mây, cho phép các công ty thuê bên ngoài cài đặt hệ thống và quản lý phần cứng với một chi phí cố định hàng tháng.
Bởi vì các giải pháp HDFS đều lưu trữ và xử lý dữ liệu trên mỗi node làm việc, chúng đảm bảo rằng chúng ta có đủ sức mạnh tính toán để giải quyết các vấn đề dữ liệu của chúng ta. Khi dữ liệu tăng kích thước, số lượng node có thể được tăng để thêm nhiều không gian lưu trữ và sức mạnh tính toán hơn. Điều này có lợi thế cho việc mở rộng nhưng có thể trở nên đắt đỏ khi số lượng nút tăng lên.
Đối Tượng Lưu Trữ
Một loại hệ thống tệp phân tán khác đang nhanh chóng trở nên phổ biến vì nó phân tách lưu trữ khỏi sức mạnh tính toán. Lưu trữ đối tượng là một framework chỉ dành cho việc lưu trữ để chúng ta có thể sử dụng bất kỳ loại sức mạnh tính toán hoặc framework nào trên dữ liệu của chúng ta. Các nhà cung cấp đám mây như Microsoft Azure, Amazon Web Services (AWS) và Google Cloud lưu trữ các lớp lưu trữ đối tượng, nơi chúng ta có thể lưu trữ bất kỳ loại tệp và tập dữ liệu nào.
Các lớp lưu trữ này có ưu điểm hơn HDFS ở chỗ chúng có rào cản thấp và rất linh hoạt. Người dùng có thể lưu trữ bất kỳ loại tệp nào trong một loạt các định dạng, từ CSV và Parquet đến các định dạng mã nguồn mở khác cung cấp hiệu suất và đáng tin cậy tốt hơn như Delta và Iceberg. Sự phân tách này cũng cho phép chúng ta mở rộng cả lưu trữ hoặc sức mạnh tính toán một cách độc lập với nhau để đáp ứng nhu cầu một cách hiệu quả hơn.
Post Comment