





Dùng Jsoup-Java Để Crawl Truyện Onepiece

Là một Fan chân chính của Onepiece, lúc nhỏ, tôi thường hay la cà ở thư viện, ở nhà sách để tìm đọc và mua những tập truyện.
Lớn lên, tôi được tiếp xúc với máy tính, với Internet, với bộ môn thể thao điện tử đầy balace và healthy, tôi vẫn duy trì niềm đam mê với OP. Đã có thời gian, tôi cuồng Onepiece tới mức tải cả tá chap truyện về máy tính cùng với hàng trăm Mb ảnh và hình nền Onepiece – có thể gọi tôi là thằng wibu chính hiệu (nhưng giờ đỡ rồi). Quãng thời gian đó, việc click vào từng tấm ảnh trên web và tải về làm tôi khá bực và tôi ước có công cụ gì đó để tải một loạt ảnh về máy để mình còn rảnh tay ngắm nghía chân dung của Nami-chan <3. Tôi sống chung với nỗi bực mình đó mấy năm trời, cho đến ngày tôi biết cách sử dụng Jsoup để crawl data.
Và đó là lí do bài viết này ra đời.
Crawl data là gì ?
Crawl dữ liệu hay còn gọi là cào dữ liệu là một thuật ngữ không có gì là xa lạ trong ngành marketing, dịch Vụ Seo. Vì crawl là kỹ thuật mà các robots của các công cụ tìm kiếm phổ biến hiện nay sử dụng như Google, Yahoo,… Crawler có công việc chính là thu thập dữ liệu từ một trang web bất kì, hoặc chỉ định trước rồi phân tích cú pháp mã nguồn HTML để đọc dữ liệu và bóc tách thông tin dữ liệu theo yêu cầu mà người dùng đặt ra hoặc các dữ liệu mà Search Engine yêu cầu. Với Google, họ crawl data của những trang web, đánh chỉ mục chúng để phục vụ cho công cụ tìm kiếm.
Ở những công ty bán sản phẩm, họ cần lấy tất cả các comment, các feedback của khách hàng trên web để phục vụ cho chiến lược kinh doanh. Thay vì thuê người để coppy-paste từng comment, học dùng tool để crawl dữ liệu rồi lưu vào database – nhanh chóng hơn, chính xác hơn và chi phí rẻ hơn.
Một ví dụ cụ thể hơn với sinh viên ngành công nghệ, khi tạo database, chúng ta phải viết tay hàng trăm, thậm chí hàng ngàn dòng code để insert dữ liệu. Điều này tốn quá nhiều thời gian và công sức, tiềm ẩn rủi ro sai sót dữu liệu lớn. Việc crawl data sẽ giúp chúng ta thu thập thông tin nhanh hơn, chính xác hơn, tiết kiệm được hàng tá thời gian và công sức.
Jsoup là cái chi chi ?
Jsoup là Java HTML Parser. Nói cách khac Jsoup là một thư viện Java được sử dụng để phân tích tài liệu HTML. Jsoup cung cấp các API dùng để lấy dữ liệu và thao tác dữ liệu từ URL hoặc từ tập tin HTML. Nó sử dụng các phương thức giống với DOM, CSS , JQuery để lấy dữ liệu và thao tác với dữ liệu.
Cụ thể, bạn có thể dùng Jsoup để lấy dữ liệu từ một trang web dạng code HTML, sau đó, bạn có thể dùng những hàm mà Jsoup cung cấp để lấy dữ liệu trong các class, các tag của file HTML đó. Dữ liệu bạn muốn lấy có thể là link một bức ảnh trong thẻ <img>, link một liên kết trong thẻ <a>, hay một đoạn text trong thẻ <p>,….
Cách cài đặt Jsoup
Có hai cách để các bạn cài đặt Jsoup đó là add thư viện .Jar hoặc dùng Maven project.
Cụ thể các bạn có thể tham khảo tại đây : https://jsoup.org/download
Cách lấy dữ liệu từ HTML
Ban đầu, bạn dùng Jsoup để lấy một đối tượng Document từ một URL hoặc một file HTML. Jsoup định nghĩa những dữ liệu trong các thẻ, các class là các Element. Để lấy được các Element, bạn có thể dùng những hàm trong class Document, ví dụ như String title() sẽ lấy title của trang HTML đó. Element body() sẽ trả về nội dung phần Body của trang HTML, Elements getElementsByClass() sẽ trả về tất cả các Element trong class đó, ……
Các hàm phổ biến của Jsoup
Jsoup có ba class chính đó là :
- org.jsoup.Jsoup
- org.jsoup.nodes.Document
- org.jsoup.nodes.Element
- Class Jsoup:
Class Jsoup cung cấp những hàm để lấy Document từ một file HTML hoặc một URL, ví dụ hai hàm dưới đây :
static Connection connect(String url).get(): Lấy Document của một trang web bằng URL
static Document parse(String html) : Phân tích mã HTML và trả về đối tượng Document
2. Class Document
Class Document cung cấp những hàm để lấy dữ liệu trong trang HTML theo nhiều cách
- Element body() : Truy cập vào phần tử body của tài liệu HTML.
- Element head() : Truy cập vào phần tử head.
- String title() : Trả về title của tài liệu.
- String location() : Trả về URL của tài liệu này.Trả về URL của tài liệu này.
- Elements getAllElements() : trả về tất cà các Element của tài liệu.
- Elements getElementByClass(String className) : Trả về Elements trong class.
- Elements getElementByAttribute(String key) : Trả về Elements theo thuộc tính
3. Class Element
Do cấu trúc của file HTML gồm nhiều tag, mỗi tag lại bao gồm nhiều tag nhỏ bên trong nên một Element có thể bao gồm nhiều Element con.
- Elements getAllElements() : trả về tất cà các Element con của Element hiện tại.
- Elements getElementByClass(String className) : Trả về Elements con trong Element hiện tai có class name giống với className truyền vào.
- Elements getElementByAttribute(String key) : Trả về Elements con theo thuộc tính.
Dùng Jsoup để crawl truyện Onepiece
Là một fan của Onepiece trên dưới 8 năm, tôi luôn mong có một ngày mình làm một thứ gì đó thật ý nghĩa. Tiếp xúc với JSoup, việc đầu tiên tôi muốn làm là xây dựng một App có thể crawl hết hơn 900 chap truyện. Đời vốn không như mơ, vì một vài lí do về bảo mật, tôi đã không thể dowload truyện về được. Tôi vẫn không nản chí, quyết tâm viết tool crawl hơn 10 trang web có truyện Onepiece và khi tôi sắp mất kiên nhẫn, tôi đã tìm được trang có thể crawl.
Dài dòng thế đủ rồi, bây giờ tôi sẽ hướng dẫn anh em crawl truyện trên trang https://bigtruyen.net/one-piece-full-mau/ . Dù series chỉ có gần 200 chap nhưng vẫn có thể crawl được là may rồi (T_T).
1, Phân tích HTML
Vào trang web và ấn F12, màn hình hiện ra như sau
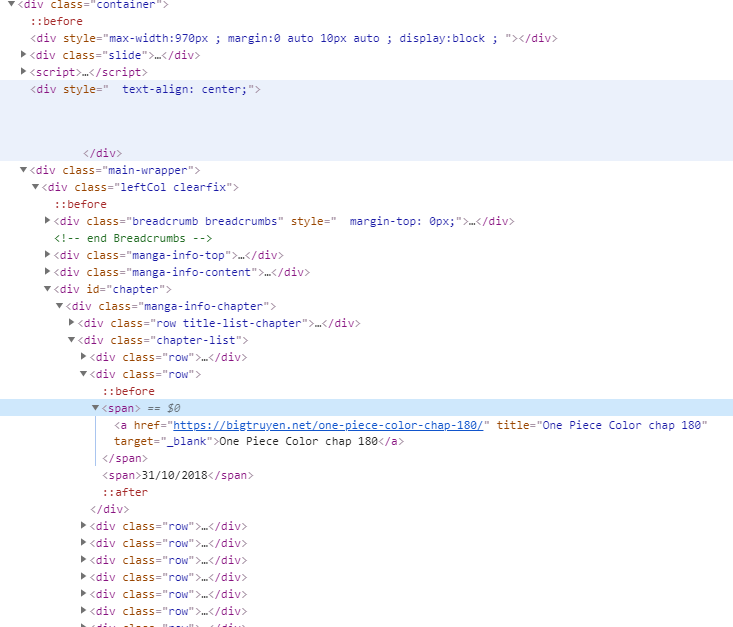
Ta có thể thấy một cách dễ dàng, những chap truyện Onepiece được viết trong thẻ <a>, class “row”. Easy !!
Trước tiên, tạo class Chap để biểu diễn các Chap
public class Chap {
private String url;
private String chap_number;
public Chap(String url) {
this.url = url;
chap_number = chapNumber(url);
}
public String getUrl() {
return url;
}
public String getChap_number() {
return chap_number;
}
private String chapNumber(String url){
int idx = 0;
for (int i = 0; i < url.length(); i++) {
if(Character.isDigit(url.charAt(i))){
idx = i;
break;
}
}
return url.substring(idx,url.length()-1);
}
}Tôi dùng hàm sau đây để lấy list URL các chap truyện.
private ArrayList<Chap> getAllChapInPage(String urls) throws IOException {
ArrayList<Chap> list_chap = new ArrayList<>();
Document document = Jsoup.connect(urls).get();
Elements elms = document.getElementsByClass("row");
for (int i = 0; i < elms.size(); i++) {
Elements elm_row = elms.get(i).getElementsByTag("a");
for (int j = 0; j < elm_row.size(); j++) {
String link_chap = elm_row.first().absUrl("href");
list_chap.add(new Chap(link_chap));
}
}
return list_chap;
}Có list các chap truyện rồi, tôi sẽ lấy một đường link, vd chap 180 đi. Dưới đây là code HTML của chap :
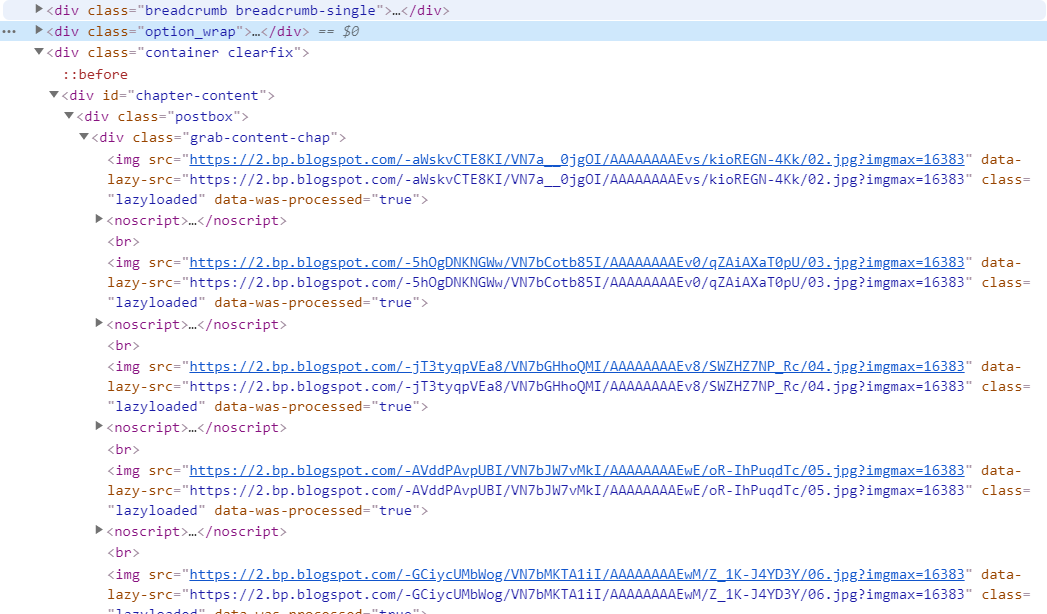
Lần này, các ảnh được biểu diễn trong thẻ <img>, bên trong class grap-content-chap, để lấy được các link ảnh, ta làm như sau
private ArrayList<String> listImgOnPage(String pageURL) throws IOException {
Document document = Jsoup.connect(pageURL).get();
ArrayList<String> list_img = new ArrayList<>();
Elements elms = document.getElementsByClass("grab-content-chap");
Elements e = document.getElementsByTag("img");
for (int i = 0; i < e.size(); i++) {
String url = e.get(i).absUrl("src");
if (url.equals("")) {
continue;
}
list_img.add(url);
}
return list_img;
}Lấy được link ảnh, chúng ta thực hiện nốt bước còn lại đó là dowload ảnh về máy.
// lưu IMG
private void saveImg(String src_image, String name, String dir) {
try {
URL url = new URL(src_image);
InputStream in = url.openStream();
OutputStream out = new BufferedOutputStream(new FileOutputStream(dir + "\\" + name));
for (int b; (b = in.read()) != -1;) {
out.write(b);
}
out.close();
in.close();
} catch (Exception e) {
JOptionPane.showMessageDialog(null, "Can not Dowload File !");
}
}Các thông số
- String src_image : link ảnh.
- String dir : đường dẫn để lưu ảnh. ví dụ “C:\\User\\dowload”.
- String name : tên của ảnh mà bạn đặt.
Kết quả
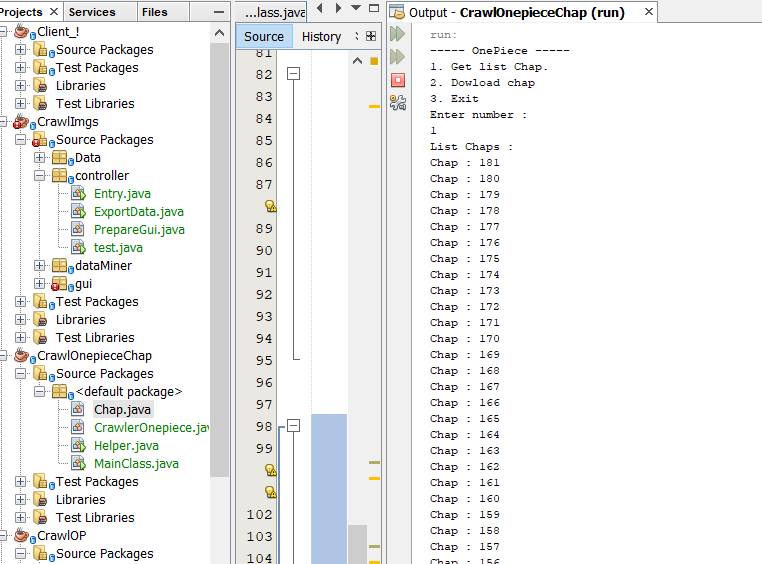
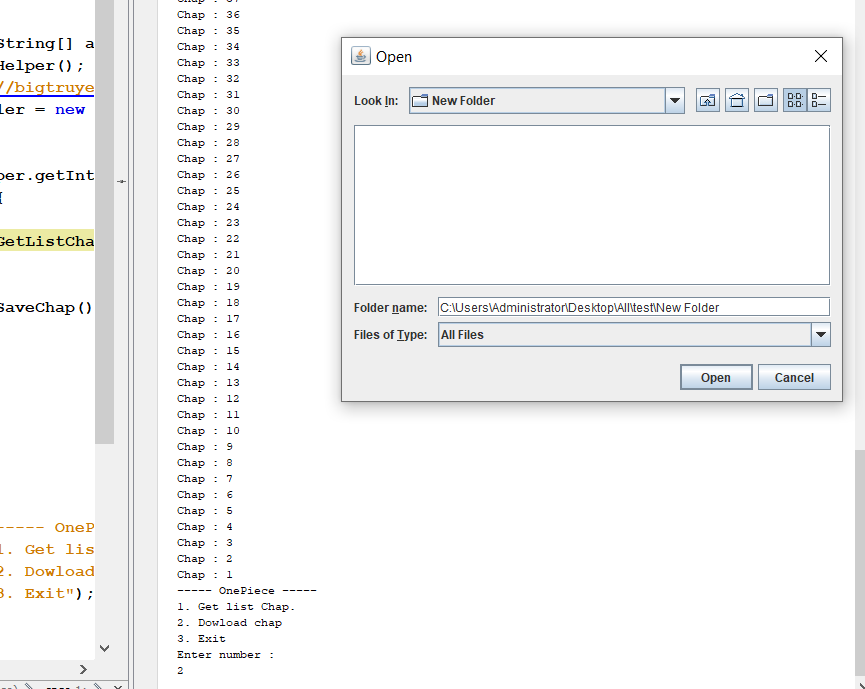
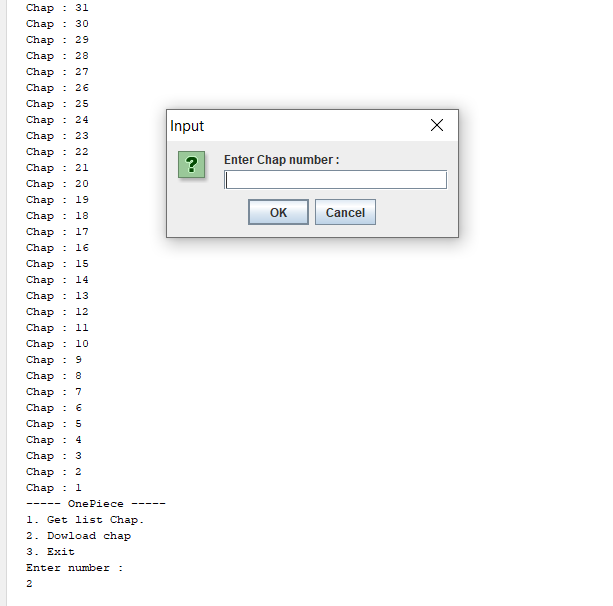
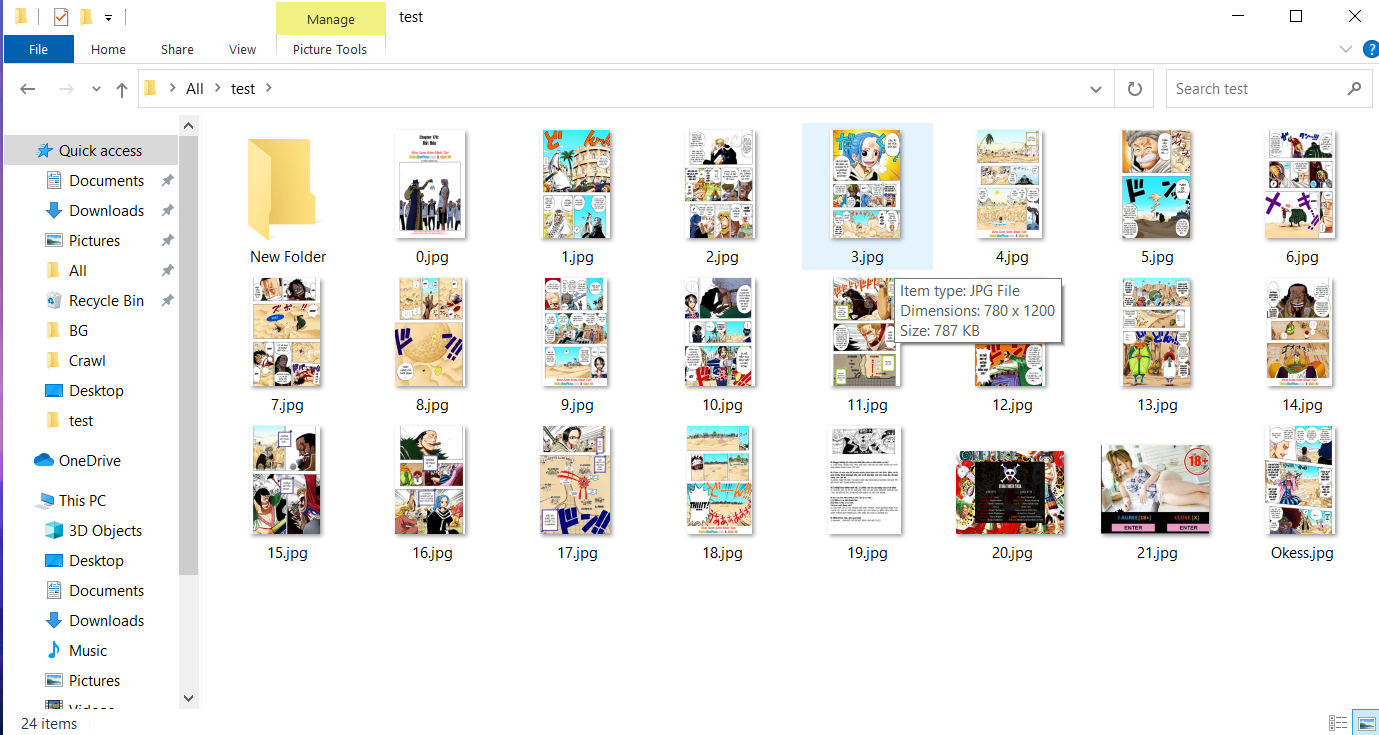
Anh em có thể tham khảo project hoàn chỉnh của mình tại đây: CrawlOnepieceChap
Tạm kết
Như vậy sau bài này, mình đã hướng dẫn anh em sử dụng Jsoup để crawl dữ liệu từ trang web. Trước khi kết thúc, mình muốn khuyên anh em chỉ nên crawl data phục vụ cho việc học, không nên phục vụ cho mục đích thương mại, hoặc nếu phục vụ cho mục đích thương mại thì phải được chủ sở hữu dữ liệu đồng ý.
Anh em nào có thắc mắc hay trao đổi, nhận xét thì hãy comment xuống phía dưới để mình được biết. Cám ơn anh em đã đọc.
Post Comment