





AlphaGo: Trận Đấu Lịch Sử Với Đại Kỳ Thủ Cờ Vây (Phần 2)

Ở phần trước, mọi thứ đã sẵn sàng. Trí tuệ nhân tạo đương đầu với đỉnh núi cao nhất của Cờ vây. Đâu mới là giới hạn của AI? Hãy cùng theo dõi và phân tích 5 ván đấu nghẹt thở qua từng chặng.
Ván 1 (9/3/2016)
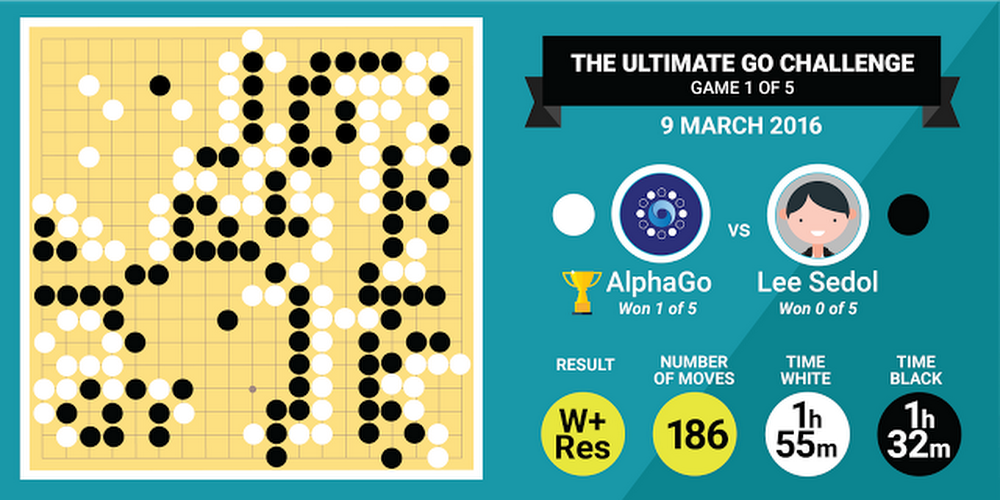
Trong ván đấu đầu tiên này, AlphaGo cầm quân trắng. Lee Sedol đi trước. Lee đã giành quyền kiểm soát trong hầu hết cả ván đấu, nhưng AlphaGo đã đạt được lợi thế trong 20 phút cuối và Lee Sedol đã chịu thua. Trận đấu kết thúc sau 186 nước đi. Đen 123 và Đen 129 là lỗi sai cuối cùng của Lee và anh đã không thể lật ngược tình thế. Lee tự trách mình với lỗi sai ở Đen 123 và 129 ngay sau khi ván đấu kết thúc.
Ván 2 (10/3/2016)
AlphaGo cầm quân đen trong ván đấu thứ hai và có lợi thế đi trước đã tiếp tục giành chiến thắng. Lee Sedol sau đó đã nói rằng “AlphaGo có một ván đấu gần như hoàn hảo”. Nước đi 37 của AlphaGo được đánh giá là một nước đi vô cùng đẹp, sáng tạo và độc đáo. AlphaGo đã cho thấy những sự dị thường từ các nước đi, nó nhìn ở một khía cạnh rộng hơn khi các kỳ thủ Cờ vây chuyên nghiệp nghĩ rằng đó là một nước đi sai lầm nhưng thực ra AlphaGo đã đi một nước đi có chủ ý.

Ván 3 (12/3/2016)
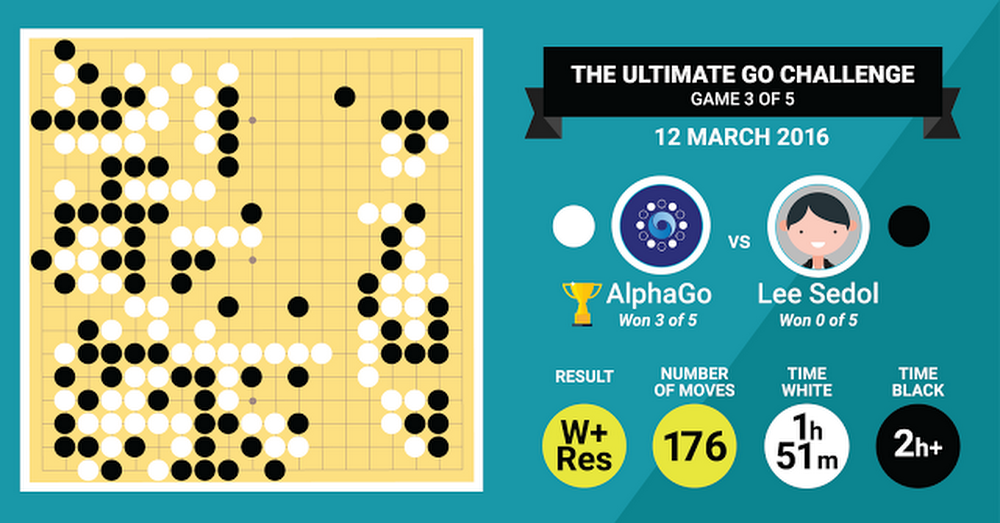
Ván thứ ba AlphaGo cầm quân trắng. Nó đã có một trận đấu vô cùng thuyết phục và thực tế nó đã chơi tốt đến mức…gần như là đáng sợ. Trận đấu kết thúc ở nước đi thứ 176 và AlphaGo đã viết nên lịch sử khi có 3 chiến thắng liên tiếp trước Lee Sedol.
Ván 4 (13/3/2016)
Ván thứ tư là một ván đấu đặc biệt. Lee Sedol đã giành được chiến thắng đầu tiên trước AlphaGo. 3 chiến thắng liên tiếp đã khiến nhà bình luận Chris Garlock phải thốt lên “Liệu AlphaGo có điểm yếu nào không?”. Thế nhưng, trong ván đấu thứ tư này, AlphaGo đã mắc phải một sai lầm lẽ ra không đáng có ở nó: Quá tự tin. Nước đi thứ 78 của Lee Sedol được mô tả là “thần thánh” (Lee Sedol magic!) và ở ngay nước đi sau đó, AlphaGo đã mắc sai lầm. Tỉ lệ thắng mà nó ước tính đang ở 70% đột nhiên giảm mạnh ở nước đi thứ 87. Lee Sedol khiến AlphaGo phải “đầu hàng” sau 180 nước thi đấu. Chiến thắng này có ý nghĩa rất lớn với Lee Sedol và những người cổ vũ. Nó thể hiện rằng trí tuệ của con người vẫn có thể đứng vững, mặc dù trong tương lai có lẽ sẽ rất khó để đánh bại AI.

Ván 5 (15/3/2016)
Ván đấu thứ năm, Fan Hui cho rằng “Dường như điểm yếu của Lee Sedol lại quay trở lại khiến anh ấy có một số nước đi rất tệ.” Ván đấu kết thúc nhẹ nhàng với chiến thắng giành cho AlphaGo sau 280 nước đi.

Kết quả chung cuộc: AlphaGo 4-1 Lee Sedol
Bài học từ AlphaGo
Nam Chi-hyung (Giáo sư nghiên cứu Cờ vây – Đại học Myongji): “Chúng ta đã nói nhiều về những nước đi rất “dị” và kỳ lạ của AlphaGo, trông thì có vẻ như đó là nước đi lỗi. Cho đến khi ván đấu kết thúc, chính chúng ta phải nghi ngờ về bản thân mình, nghi ngờ về những đánh giá của mình.”
Frank Lantz (Giám đốc Trung tâm Trò chơi – Đại học New York): “Với tôi, điều thú vị nhất mà tôi học được ở trò chơi này xuất phát từ việc xem cách mà AlphaGo chơi, nó gọi là “những nước đi chùng xuống”. AlphaGo muốn dạy cho chúng ta một điều, chúng ta đang quá phụ thuộc vào điểm số, và dựa vào đó để xác định cơ hội giành chiến thắng. Ở thời điểm này bạn có thể vây được nhiều đất hơn, có được nhiều điểm hơn, tôi đang ít điểm và thất thế, điều đó không có nghĩa là bạn sẽ thắng. Tôi chỉ cần một điểm nút duy nhất để đảo ngược tình hình. Tại sao tôi phải giành thêm đất trong khi tôi không thực sự cần đến nó? Đó là điều mà AlphaGo muốn thay đổi chúng ta về cách nhìn nhận trò chơi này trong tương lai.”
Lee Sedol: “Điều làm tôi bất ngờ nhất là cách AlphaGo chỉ cho chúng ta những nước đi mà con người nghĩ rằng “thật sáng tạo”, thực chất với nó lại là rất bình thường.”
Cùng theo dõi diễn biến chính được highlight tại đây “Hành trình AlphaGo đánh bại Lee Sedol”
Bình luận
DeepMind đã sử dụng công nghệ mạng lưới thần kinh – mô phỏng mạng nơ ron thần kinh của não người cho AlphaGo. AlphaGo tự học chơi cờ vây bằng cách phân tích hàng ngàn hàng vạn nước đi của người chơi trước. Sau đó, kết hợp với công nghệ học tăng cường (reinforcement learning), nó tự chơi cờ với chính bản thân mình để đẩy trình độ của mình lên các đẳng cấp cao hơn. Về bản chất, các lần tự chơi này giúp tạo ra các nước đi mới mà máy tính có thể sử dụng để đào tạo lại chính bản thân. Vì vậy, đây không phải là nước đi của con người. Nói cách khác, hệ thống AlphaGo không vận hành để chơi theo cách thông thường, nó chơi theo cách con người sẽ không bao giờ làm.
Chiến thắng chung cuộc 4-1 của AlphaGo trước Lee Sedol là một cột mốc quan trọng trong nghiên cứu Trí tuệ nhân tạo. Nó đã đập tan quan điểm cho rằng “máy tính sẽ không bao giờ đánh bại được những người hàng đầu trong Cờ vây.” Nó là động lực để các chuyên gia DeepMind tiếp tục phát triển thêm các phiên bản nâng cấp như Alpha Zero hay Alpha Star sau này.
Còn với các bạn trẻ muốn tìm hiểu và nghiên cứu sâu hơn về AI, hãy bắt đầu nuôi dưỡng niềm đam mê AI ngay từ hôm nay nhé. Chúc các bạn thành công
Post Comment