





Explainable AI – Giải Thích AI Bằng Cách Nào?

Trong bài lần trước về Explainable AI (XAI), mình đã giới thiệu qua cho mọi người về khái niệm và lý do vì đâu người ta lại tập trung vào lĩnh vực này. Lần này mình sẽ giới thiệu cho mọi người một số phương pháp tạo ra các lời giải thích cho mô hình cùng với những tiêu chí mà một lời giải thích tốt cần phải có.
Một lời giải thích tốt cần những gì?
Sự dễ hiểu, đúng vậy, cái chúng ta cần là giải thích cho người khác, có thể là đồng nghiệp hoặc khách hàng – người có ít kiến thức về AI hiểu cách mô hình hoạt động thì lời giải thích này phải ở mức dễ hiểu nhất; chúng ta không thể nào vẽ biểu đồ như vầy cho một mô hình cây quyết định để giải thích được.
Bạn không thể nào hình dung được nó là gì cho dù có phóng to lên, quá phức tạp. Ít nhất nó phải ở mức như hình dưới:
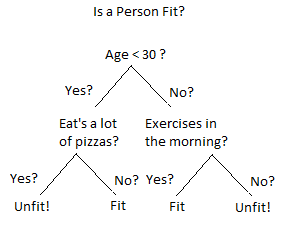
Trực quan, rõ ràng và tất nhiên là dễ hiểu hơn sơ đồ phía trên nhiều lần.
Sau khi có một lời giải thích cho con người có thể hiểu thì tiếp theo cái chúng ta cần là sự đúng đắn; ta đưa ra sự giải thích cho một trường hợp nhất định một dữ liệu kiểm tra nhất định nhưng không có nghĩa là mẫu kiểm tra này đại diện được cho toàn bộ mô hình. Bởi vì ở riêng từng trường hợp đặc trưng này có thể ảnh hưởng lớn nhất nhưng không thể nào quy chụp đặc trưng này cho toàn bộ các dữ liệu trong tập kiểm thử được. Nói đi cũng phải nói lại, một mẫu kiểm thử không đủ để đại diện cho toàn mô hình thì ta chọn nhiều mẫu dữ liệu kiểm thử và cần phải đảm bảo rằng một số dữ liệu chúng ta chọn ra này là những dữ liệu có thể đại diện được cho mô hình.
Tiêu chí cuối cùng cũng quan trọng không kém là phương pháp giải thích mô hình đang thực hiện phải có được tính khái quát, tức là một phương pháp giải thích cần sử dụng được cho nhiều loại mô hình khác nhau. Như chúng ta đã biết hiện tại có rất nhiều mô hình khác nhau, chúng ta không thể nào với mỗi mô hình lại cho ra một phương pháp giải thích được; cái ta cần là một cái gì đó tổng quát.
Sự dễ hiểu vs Độ chính xác
Ở đây ta có hai hướng để đưa ra lời giải thích cho mô hình để đảm bảo đầy đủ các tiêu chí được đề cập bên trên.
Một là xây dựng những mô hình tường minh dễ hiểu, như các mô hình hồi quy, đa phần là các công thức toán học mà đã là công thức thì có thể giải thích một cách dễ dàng được. Ví dụ với mô hình Hồi Quy Tuyến Tính (Linear Regression) về cơ bản là một phương trình có dạng
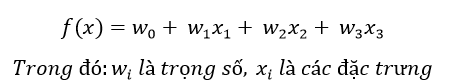
Đặc trưng nào có trọng số lớn thì có ảnh hưởng, tầm quan trọng lớn hơn và ngược lại; vô cùng đơn giản dễ hiểu.
Nhưng các mô hình đơn giản lại không đạt được độ chính xác cao ở các bài toán phức tạp bằng các mạng học sâu. Chúng ta có một sự đánh đổi giữa độ dễ hiểu và độ chính xác trong các dự đoán của mô hình ở đây.
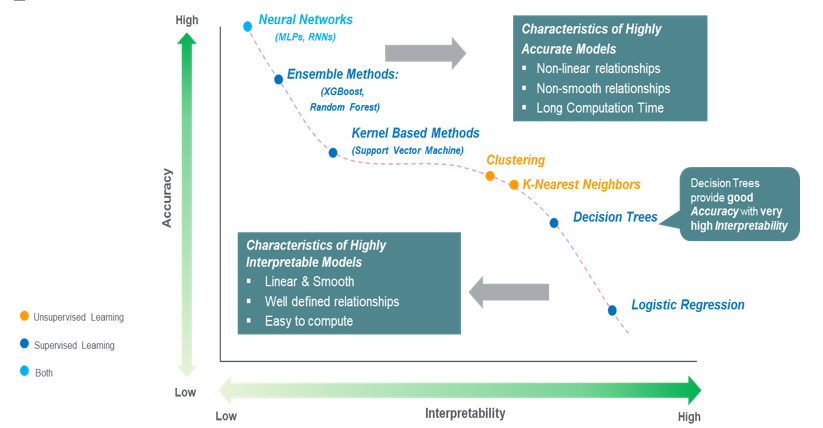
Những mô hình càng đạt được đô chính xác cao, theo một nghĩa nào đó là càng tốt thì sự dễ hiểu càng thấp. Sự dễ hiểu và độ chính xác đối với các mô hình học máy, học sâu đang là hai đại lượng tỷ lệ nghịch với nhau. Mặt khác, khi gặp trường hợp có dữ liệu quá phức tạp hoặc quá nhiều đặc trưng, như những bài toán phân loại văn bản thì mỗi từ cũng đã là một đặc trưng rồi và ta có cả trăm cả ngàn từ, thì những mô hình dễ hiểu cũng sẽ không còn dễ hiểu nữa.
Thế có cách nào để giúp chúng ta có thể hiểu được các mô hình tốt khi bản thân chúng như những “black-box” – hộp đen máy bay. Câu trả lời là có và cách tiếp cận này trong việc giải thích các mô hình được gọi là các phương pháp hậu học (post-hoc).
Một số phương pháp
Trong hướng tiếp cận hậu học thì có vài phương pháp khá thú vị như LIME (Local Interpretable Model-agnostic Explanations), SHAP (Shapley Additive exPlanations), Influence Functions, Integreated Gradient, ….
LIME là phương pháp đưa việc to hóa nhỏ, thay vì giải thích cho toàn cục thì ta đưa sự việc về địa phương (local) và biểu thị ra cho bạn phần nào trong dữ liệu ảnh hương nhiều nhất tới dự đoán của mô hình

Như hình trên, mô hình dự đoán đó là chó Labrador bởi vì các điểm ảnh ở mặt của chú chó này.
Trong khi đó SHAP là phương pháp sử dụng kiến thức từ Lý thuyết trò chơi và Thống kê để đưa ra được mức độ ảnh hưởng của các đặc trưng.

Theo ảnh trên thì các điểm màu hồng chính là các điểm ảnh quan trọng, những điểm để “đại diện” cho nhãn được xem xét. Có thể với hình cầy vằn (cầy Meerkat) thì phần mặt chính là điểm giúp nhận diện tốt nhất; còn thử với nhãn là cầy lỏn (cầy Mangut) thì gần như không có điểm ảnh nào đại diện cho nhãn này cả.
Tạm kết
Như vậy, chúng ta đã rõ hơn một số tiêu chí cho việc giải thích mô hình cũng như biết về một số phương pháp giải thích. Thế những phương pháp này hoạt động như thế nào? Tại sao nó có thể chỉ ra chính xác những điểm ảnh đại diện cho nhãn? Liệu với dữ liệu văn bản, dữ liệu dạng bảng thì các phương pháp này sẽ biểu diễn các đặc trưng ra sao?
Xin hẹn các vị độc giả ở số tiếp theo.
Post Comment